
GENEXII学习笔记
The First Section: Gene is DNA that encodes RNA and polypeptides
Terminology
- Genome/基因组: 脱氧核糖核酸(deoxyribonucleic acid,DNA)链提供了有机体,以及它的每一个细胞所携带的全部遗传信息。它包括染色体DNA、质粒DNA,以及(真核细胞中)存在于线粒体和叶绿体的细胞器DNA。
- protein—coding gene、结构基因(structural gene):编码的RNA依次编码多肽。
- gene locus: 每一条染色体由线性排列的基因组成,每个基因位于染色体的特殊位点上。
- allele : 基因座上所发现的不同形式。
- linkaage : 一条染色体上的等位基因表现出连锁遗传。
- transfection: 转染,指纯化的DNA加入到动物细胞中产生特殊的蛋白质。
- nucleotide:在C-5与磷酸基团相连的核苷称为核苷酸。
- supercoiling : DNA双螺旋结构自身相互缠绕从而改变DNA分子空间构象。同向扭转(顺时针)正超(positive),反之负超。
- lingking number(L) : DNA一条链绕另一条链的环绕圈数。不同L的NDA分子称为拓扑异构体。
- writhing number(W) : DNA双链的轴所绕圈数,无量化值,W=0则为松散分子。
- twisting number(T) : 一条链相对于另外一条的旋转情况。由每圈多少个碱基决定。
- L~0~为松散状态L, L/L~0~可视为超螺旋密度。
- bent DNA:一条链上出现8~10个连续腺嘌呤(A)导致双螺旋弯曲。
- melting temperature: 使DNA双链分开的温度范围的中点。
- hybrization : 两条不同来源的互补核酸序列退火形成双链结构。
- 滤膜上吸附有变性DNA,置于含有其他变性DNA的溶液中,即可检测是否含有互补序列。检测紫外吸收峰值测定杂交程度或是通过放射性强度决定。
- mutation rate: 贯穿全基因组的突变(突变率以每个基因组每代发生多少来表示):基因内的突变(突变率以每个基因座每代发生多少来表示):特殊核苷酸位点的突变(突变率以每个碱基每代发生多少来表示)。
- transposable element: 具有可从一个位置移动到另一个位置的DNA序列。这一插入往往导致基因活性消失造成移码突变(frameshift mutation)。
- 插入发生时往往会删除部分或者全部插入序列,邻近区域也可能被删除。
- forward mutation:正向突变,使基因失活的突变。相对应的是back mutation,回复突变。
- true reversion:真实回复。原始突变的严格逆转。
- second-site reversion:第二位点回复。第二次突变弥补了第一次的功能。
- suppression mutation: 一个基因座上的突变能够抑制另一个的突变效应。该locus称为抑制基因(suppressor)
- 点突变可能导致多肽的氨基酸替换,而tRNA基因上的一种突变使得它能识别突变的密码子,那么在翻译中就会插入原来的氨基酸残基(请注意:这抑制了原来的突变,但在其他mRNA的翻译中会引入错误)。
- cistron: 处于顺式构型或是反式构型的基因是指两个突变是否在同一条链上。
- null mutation: 基因功能被完全消除。
- loss-of-function mutation: 阻止基因功能的突变。
- leaky mutation: 突变不完全消除蛋白质活性,保留一定活性。
- silent mutation: 无明显效应的突变。
- synonymous mutation: 碱基改变但是氨基酸残基不变。
- neutral substitution: 碱基改变,氨基酸残基也改变,但多肽活性不变。
- 中性突变(neutralmutation) : 它对有机体表型没有影响。
- 一些中性突变是同义突变,但不是所有的同义突变都是中性的。具体运送特定氨基酸的单一RNA的浓度是不同的,一些同义tRNA(不同tRNA携带一样的氨基酸)比其他的丰富,一些特殊密码子可能缺少足够的tRNA;
- frameshift mutation移码突变:吖啶acridine引起,引进或者缺失一个碱基。(-)和(+)两种,分别表示缺失与增加。同时(+)(-)和(-)(+)两种方式可相互抑制,一个称为另一个的移码抑制基因(frameshift suppressor)。
- 当构建三突变体时,只有(+++)和(—-)表现野生型表型,而其他组合都是突变型。
- 错义突变(missense mutation): 产生编码不同氨基酸的密码子;
- 无义突变(nonsense mutation): 产生终止密码子。
- reading frame:阅读框,如果遗传密码是不重叠的三联体,根据起始位点的不同,那么会有3种可能的方式将核苷酸翻译成蛋白质。
- 一个由能翻译成氨基酸的三联体构成的阅读框称为可读框(open reading frame,ORF)。
- 多肽序列有一个特殊的起始密码子(initiation codon)(AUG),从此延伸出一系列代表氨基酸的三联体,直到遇到3种类型的终止密码子(termination codon)(UAA、UAG或UGA)中的一个时才结束翻译。
- 如果终止密码子频繁出现,就会阻止阅读框被翻译成蛋白质,我们称之为关闭(closed)或阻断(blocked):如果一个序列的3个阅读框全部被阻断,那么它就失去编码蛋白质的功能。
- 在3种可能的阅读框中,只有一种阅读框是可翻译的,而其他两种会受到频繁的终止信号的阻断。
- colinear: 基因与蛋白质是否共线性。核苷酸序列与蛋白质中氨基酸序列是否恰好一致。如果一个多肽含有N个氨基酸残基,那么编码这一多肽的基因就包含3N个核苷酸残基。
- gene expression : 用来自基因中的信息合成RNA或多肽的过程称为基因表达。
- mRNA还包括两边的附加序列,这些序列不编码蛋白质
- 5’端的非翻译区称为前导区(leader)或5’非翻译区(5’untraslatedregion,5’UTR).
- 3’端的非翻译区称为非翻译尾区(trailer)或3’非翻译区(3’untraslated region,3’UTR).
- cis-acting: 顺式作用。DNA序列包含两个部分,控制位点和编码区,控制位点的缺陷仅仅影响与其相连的编码区,而这不影响其他等位基因的表达能力,这种仅影响邻近DNA序列表达的性质称为顺式作用(cis-acting)。
- trans-acting:反式作用,调节物突变。如果突变能发挥反式作用,我们就认为其作用是通过产生可扩散分子(通常是蛋白质或调节性RNA)进行的,它可作用于细胞内多个靶标;
Key concepts
- 碱基配对互补:
- 一条单链分子中两段互补序列通过碱基配对可以形成分子内的双链体。
- 一条单链分子可以和另一条独立、互补的单链分子进行碱基配对,形成分子间的双链体。
- 突变(自发或诱发)只需要在单链形成即可。
- 突变热点的出现是多个突变事件在一个位点发生的结果。
- 热点的存在是因为胞嘧啶发生了高频率的自发脱氨基,从而产生尿嘧啶,而甲基化的胞嘧啶脱氨基则产生胸腺嘧啶!
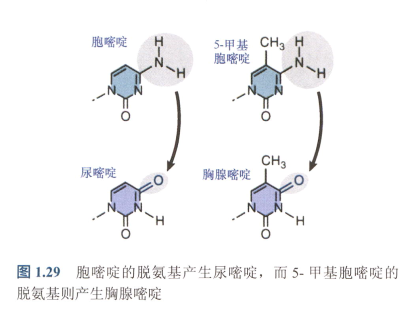
- 由于U不存在于DNA中,故而胞嘧啶脱氨基能够很快被识别。
Inexplicable points
- 为什么处于解链温度DNA双链体是稳定的?(comes from GENE XII P16)
Interrupted gene
Terminology
- interrupted gene: 断裂基因,编码区和非编码区互相间隔开但又连续镶嵌而成
- 外显子(exon)的序列包含在成熟RNA中,精确地说,一个成熟转录物(maturetranscript)起始于一个外显子的5’端,终止于另一个外显子的3’端。
- 内含子(intron)是插入序列,在初始转录物加工成成熟RNA时被除去。
- 反式剪切:不同mRNA的序列连接到一起
- First parity rule: 即碱基配对原则
- second parity rule: 在双链的每条单链中AT,CG几乎相等,也即碱基对不是偏向某一条链,而是相对均匀的散落在两条链中;更多地适用于内含子;
- cluster rule : DNA中嘌呤和嘧啶往往分别聚集在一起,AG,CT,更多适用于外显子;
- GC rule: 一个基因组中,GC的含量的总体比例具有物种特异性;在基因组内,单一基因往往具有独特的值;
- 外显子GC含量高于内含子
- negative selection: 也称纯化选择(purifying selection), 外显子序列是保守的,因为如果序列改变(不再保守),就会导致表型的改变,这种改变会使物种难以生存和很难产生可繁殖的后代。
- overlapping gene: 同一DNA序列编码两种非同源蛋白,使用了一次以上的阅读框。
- nested gene: 一个基因被发现存在于另一个基因的大的、类似于“宿主”的内含子中
- 重叠基因往往存在于“宿主”基因的另一条链上。
- alternative splicing: mRNA前体以多种方式将exon连接在一起的过程;
- in series gene: equal to no allele;
- gene family : 为一组源自基因复制事件的、编码相关或相同多肽的基因。在第一次复制事件后,两份拷贝完全一致,随后,当不同突变在序列上累积后,它们就开始趋异。
- superfamily: 当我们发现基因相距较远,但还是认为它们具有共同的祖先, 称该组基因为超家族;
- orthologous gene : 也称ortholog, 是物种进化后所形成的同源基因(homologous gene,homolog),换句话说,它们是不同物种的相关基因。
Key concepts
- 只有外显子中的突变才会影响多肽链序列;但内含子中的突变会影响RNA的加工,从而可能影响序列和(或)多肽的产生。
- DNA碱基组成的4条规则是:第一均等规则、第二均等规则、成簇规则和GC规则。
- 我们能根据第一条之外的所有规则来区分外显子和内含子。
- 第二均等规则提示,来自双链体DNA、固定的茎-环区段的外突在内含子出现得更多。
- 不同生物间内含子的位置通常是保守的,但是相应的内含子的长度变化可以很大。
- 比较不同物种的相关基因发现,相应的外显子序列通常是保守的,而内含子序列的相似性则低得多。因为缺乏使用有用序列去产生多肽,所以没有选择压力,这样内含子比外显子进化要快得多。
- 相关性:编码序列和邻近外显子的内含子区域保持了相似性;而在更长的内含子与非编码序列两侧的区域则存在着很大的趋异。
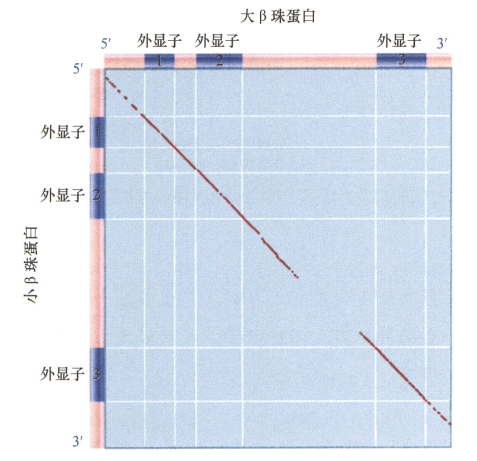
- 处于正选择下,相对于无突变的其他基因,碰巧产生有利突变的单一基因存活下来;
- 此时外显子进化要比内含子快;
- 内含子保守:
- RNA剪接所需的内含子序列,如5’和3’剪接位点,以及分支位点是保守的;
- 碱基顺序也被进化以适应于增进这个区域中双链体DNA外突茎-环结构的潜能(折叠潜能)
- 外显子通常短小,典型的外显子编码小于100个氨基酸。一个基因的总长度主要由它的内含子所决定。
- 抗体特异性的产生:抗体结构 - 知乎 (zhihu.com) 中关于超变区的描述;
Inexplicable points
- pressure 具体指什么?为什么把它说成信息?

- 选择压,就是自然选择淘汰一些表型的基因
Overview of Genome
Terminology
- genome: 有机体的一整组完全地的基因,最终由DNA的全序列决定。
- transcriptome: 在特定条件下表达的一组完整的基因,根据细胞中所存在的这一组RNA分子来决定
- proteome: 一组完整的多肽,它可由全基因组编码,或者在某一种细胞或组织中产生。
- interactome: 相互作用组,蛋白质可以独立地或者作为多蛋白组装物或多分子复合体的一部分而起作用,如全酶或代谢途径中这些酶簇拥在一起。如果我们能够鉴定出所有的蛋白质与蛋白质之间的相互作用,那么我们就能够确定独立的蛋白质组合体的数目。
- reassociation kinetics: 真核生物基因组的总体特征可以通过变性DNA的复性动力学(reassociation kinetics)来估计。
- 非重复DNA(nonrepetitive DNA)由单一序列组成,在单倍体基因组中只有一份拷贝。
- 重复DNA(repetitive DNA)是在每一单倍体基因组中含有两份以上的拷贝。重复DNA经常被分为两种类型。
- 中度重复DNA(moderately repetitive DNA)由相对较短的序列组成,在基因组中,其重复次数一般在10~1000次。
- 这些序列遍布整个基因组,并负责前mRNA剪接时二级结构的形成,此时内含子中的反向重复配对形成双链体区域。编码tRNA和rRNA的基因也是中等重复的。
- 高度重复DNA(highly repetitive DNA)由基因组中非常短的序列(一般小于100bp)组成,重复次数达几千次,一般组成长的串联重复。
- 中度重复DNA(moderately repetitive DNA)由相对较短的序列组成,在基因组中,其重复次数一般在10~1000次。
- Linkage map: 根据基因座之间的重组率来确定距离;
- restriction map:通过限制性内切核酸酶把DNA切成片段, 再测量切割位点的碱基对距离(电泳迁移)
- genetic polymerphism: 一个基因座上存在多个等位基因;
- transposon:转座子。有相当大一部分的中度重复DNA是由转座子(transposon)组成的,它们的序列比较短小(最多约5kb),能够移位到基因组中新的位置,或者进行自我拷贝。
- synteny : 同线性,不同物种基因组在局部范围内,总体上基因的排列顺序是相同的:当成对的人类和小鼠染色体同源区域进行比较时,位于对应位置的基因通常是同源的。
- expressed sequence tag: EST就是转录序列的一小部分,它通常来自于gcoreA文库中的克隆片段的一端或双末端测序。EST能证明一个所怀疑的基因确实是转录的,或有助于鉴定影响特殊疾病的基因。
Key Concepts
- 蛋白质编码的基因的最大数目:
- 根据可读框来确定
- 根据转录物组(通过直接确定所有的mRNA)或蛋白质组(通过直接确定所有的蛋白质)来直接定义基因的数目,这种方法能保证我们处理的是真实基因,即它们是在已知环境下所表达的基因。
- 非重复DNA随着全基因组的增大趋向于更长。故基因组中的非重复DNA组分与有机体的相对复杂性有较好的相关性。
- 多肽一般是由非重复DNA编码的。
- 在同一个分类群中,较大基因组并不一定含有更多基因,但包含有较多的重复DNA。
- 大部分重复DNA是由转座子组成。
- 细胞器基因组:
- 通常为环状DNA分子; 线粒体DNA — mtDNA, 叶绿体DNA — ctDNA or cpDNA;
Inexplicable points
Genome sequence and evolution
Terminology
- tandem repeat :串联重复序列,以相对恒定的短序列为重复单位,首尾相接, 串联连接形成的重复序列,又称卫星DNA (satellite DNA)。
- abundance:在每一个细胞中,每一种mRNA的平均数量被称为这个分子的丰度(abundance)。
- scarce mRNA: 也称complex mRNA, 占总量约一半的mRNA组成了大部分不同的序列,约为上万种,每一种mRNA成分的量都不是很多,通常少于10份拷贝。稀有mRNA的表达是广泛重叠的。
- constitutive gene: 约10%的mRNA序列在这个细胞中是独特的,大部分表达序列在许多、有时甚至所有细胞类型中都是相同的。这些基因是所有细胞类型所必须的。
- luxury gene: 特定细胞类型必需并只在其中表达的基因(如卵清蛋白或珠蛋白)
- microarray: 含有微陈列(microarray)的芯片,这些陈列包含一排排的、高密度的微量DNA寡核苷酸样品。这种装置是建立在全基因组序列已知的基础之上。在酵母的6181个ORF中,当我们对每一条进行分析时,我们将20条25-寡核苷酸(25-mer,它与mRNA是完全匹配的)和20条不完全匹配的等长的寡核苷酸(它们只在一个碱基位置上是不同的)用来代表同一个ORF,从完全匹配的模式中所得到的信号减去不匹配的信号,就能计算出每个基因的表达水平。
- 这一技术非常敏感;
- 不完全匹配的寡核苷酸目的是检测突变;
- transversion mutation: 从嘧啶到嘌呤或者从嘌呤到嘧啶;
- transition mutation:从嘌呤到嘌呤,嘧啶到嘧啶;
- genetic drift: 群体中突变变异体频率的随机变化称为遗传漂变(genetic drift)这是某一种基因型的“抽样误差(sampling error)”
- 可能一群特殊类型亲本的子代基因型不完全匹配孟德尔遗传定律所预测的数值;
- 在非常大的群体中,遗传漂变的随机效应往往被平均化了,所以每一种变异体的频率几乎不存在改变;
- 然而在小群体中,这些随机变化将会非常显著,遗传漂变对群体的遗传变异会产生显著的效应。
- genetic hitchhiking : 核苷酸序列以一定速率中性进化,在特定核苷酸中以这种速率进行的变异会影响杂合性(heterozygosity)(在某一基因座的杂合子的比例)。如果变异体序列是有利的,那么这个位点将显示核苷酸杂合性的降低,而变异体在频率上会增加,并最终固定于群体中;
- divergence: 趋异度, 两基因的差异。可通过在每一个位点上获取最常见碱基,就可计算一个家族的祖先共有序列。每个现存成员的趋异度用它与祖先序列的差异碱基比例来计算;
- unit evolutionary period: 单位进化时期,产生1%的趋异度所需的时间;百万年为单位;
- C-value: 活体生物基因组的DNA总量;
- C-value paradox: 基因组大小与遗传形态复杂性之间缺乏必然联系;
- CpG岛:p指的是磷酸二酯键,不是pair!!
- 哺乳动物的基因组里,CpG序列只占1%。其中70%-80%的CpG是零散分布的,但有一部分CpG会聚集成团,就像岛屿一样散布于基因的海洋里,因此得名CpG岛。CpG岛内的CpG可占据总序列长度的60%以上。
- 70%左右的功能基因的起始部位都有CpG岛存在;
- 游离的CpG序列总是处于甲基化状态,而聚成岛屿的CpG通常是没有甲基化的。甲基化后的CpG岛就无法结合转录因子(DNA链上伸出来的甲基就像刺刀一样阻止转录因子的靠近)
- nonallelic gene: 两个(或两个以上)相同基因存在于同一染色体上,这称为非等位基因;
功能基因: 即protein-coding gene, 那些首先被转录成RNA,而后被翻译为多肽的基因。
- 无功能基因指不能编码相应蛋白质的基因,它们被称为假基因,其失活的原因有多种,可能是转录或翻译的缺陷(或两者均有)所致。
- 它们不能产生携带原有功能的多肽产物;
- 它们可以是非功能性的,或产生了变异的功能,以及可具有调节功能的RNA产物。
processed pseudogene: 来自成熟mRNA转录物反转录而成的gcoreA拷贝,并被整合入基因组中;
- 当活性反转录酶存在于细胞中,如在活性反转录病毒感染时或反转座子具有活性时,这种事件可能会发生。或转录物进行过加工,其结果是已加工的假基因通常缺乏正常表达所需的调节区,故而失活。
nonprocessed pseudogene :来自多重拷贝或单一拷贝基因的其中一份拷贝的失活突变,或一个活性基因的不完全重复。
- 如果一个基因整体重复,包括调节区,那么此时即存在两个活性基因的拷贝,而一份拷贝上的失活突变不易受到负选择的影响。从而产生未加工的假基因;
- 一个活性基因的不完全重复,产生失去了调节区和(或)编码序列的拷贝,将会是“到达即死”形式,即它马上会形成假基因。
- 霍利迪连接体:https://upload.wikimedia.org/wikipedia/commons/8/8e/НеподвижнаяструктураХоллидея_%28англ.%29.svg.svg)
Key concepts
- 支原体基因组大小0.6*10^6^,人类3.3*10^9^,植物的更大;
- 原核生物85%-90%的序列都编码RNA或者多肽。
- 基因组小于1.5Mb的原核生物必定都是细胞内寄生的。也由此鉴定出一个细胞所需的最少基因数,约为1500个;
- 酵母中有6000个基因;线虫有21700个基因;果蝇有17000个基因;小型植物拟南芥有25000个基因;哺乳动物中的基因数可能有20000~25000个基因。
- 人类基因组中只有1%由外显子组成。
- 外显子只占每个基因DNA序列的约5%,因此基因组中只有约25%的序列是来自基因的外显子加内含子。
- 人类基因组约有20000个基因。
- 约60%的人类基因是可变剪接的。多达80%的可变剪接改变了蛋白质序列,因此蛋白质组约由50000~60000种蛋白质成员组成。
- 重复序列占据了人类基因组的50%以上, 主要分为5类
- 转座子(transposon)(活性或非活性的)占了重复序列的绝大部分(基因组的45%)。所有转座子都是多拷贝的。
- 转座子具有自我复制和插入到新位点的能力。它们也许只以DNA元件的形式在起作用,或者部分以RNA这种活性方式在起作用
- 一些现存的基因来源于转座子,在失去转座能力后进化成它们现在的状态
- 已加工的假基因(总共约3000个,约占总DNA的0.1%。这些序列是mRNA的反转录DNA拷贝插入到基因组而形成的)。
- 简单重复(高度重复的DNA如CA重复)占基因组的约3%。
- 区段重复(长度为10~300kb的区段模块在新的区域被重复)占了基因组的约5%。这种重复序列只有一小部分位于相同染色体上,换句话说,大部分重复区段位于不同染色体上。
- 串联重复形成了一种类型的序列模块(特别是在着丝粒和端粒处)。
- 转座子(transposon)(活性或非活性的)占了重复序列的绝大部分(基因组的45%)。所有转座子都是多拷贝的。
- 当两个或更多的基因存在冗余时,在其中一个基因上进行突变也许不会检测到效应。
- 在任何给定的细胞中,大部分基因是低水平表达的。
- 只有一小部分基因的产物是细胞类型所特有的,所以是高水平表达的。
- 当复制错误,或化学品对核苷酸的改变损害了DNA,或当电磁辐射打断或形成化学键时,而在下一次复制事件中这些损伤没有修复,那么突变就会发生。
- 转换transition mutation发生的频率是颠换transversion mutation的两倍; 原因可能如下:
- 自发转换错误比自发颠换发生得更加频繁;
- 颠换错误更加容易被检测到,并被DNA修复机制校对;
- 在种间同源基因中,通过计数同义(K~s~)和非同义(K~a~)氨基酸替换,以及计算KK的比值就可研究基因的进化历史。
- K~a~/K~s~=1说明这些基因呈中性进化,其氨基酸变化不偏向任何一方;
- K~a~/K~s~<1提示负选择,此时氨基酸替换是不利的,因为它影响了多肽活性,这样就存在自然选择压力,要在那个位置保留原来功能的氨基酸序列以维持适当的蛋白质功能。
- 当K~a~/K~s~>1时就会发生正选择。这提示氨基酸改变是有利的,可能在群体中保留下来。
- 正的K~a~/K~s~值可能是很少的,部分原因是在一长串的序列中,其平均值必须超过1。如果某基因中的单一替换正在被正选择,而两侧区域处于负选择,那么,横跨序列的平均比值实际上是负的。
- 降低DNA序列多态性的因素:负选择,遗传漂变(drift),遗传搭车(hitchhiking);
- 在RNA世界,由核酸介导的许多功能在基因组空间内相互竞争。可以看成压力pressure;
- AG压力(外显子中嘌岭富集区的压力)
- GC压力[全基因组范围内的、两组沃森-克里克(Watson-Crick)配对碱基之间、独特平衡的压力]
- 单链均等压力(全基因组范围内、在单链核酸中A和T碱基之间及G和C碱基之间的压力)
- 可能它也与后者相关,即折叠压力(全基因组范围内单链核酸的压力,不管它是以游离形式或从双链体中外突的形式获得二级或更高级茎·环结构)。
- 基因组大小与遗传复杂性之间没有必然联系。
- 生物体越复杂,它所需要的最小基因组也越大。
- 许多在分类上属于一个分类阶元的生物,它们的基因组大小却变化很大。
- 重复基因可以趋异而产生不同的基因,或其一份拷贝可能会变成失活假基因。重复基因产生差异可能有以下情况:
- case 1 : 两个基因都将变成有机体所需的。
- 两个基因编码的蛋白质产生了不同的功能
- 它们在不同时间或不同细胞类型中表达。
- case 2 : 如果上个事件不发生,那么其中一个基因很可能会变成假基因;
- 因为如果它获得了有害突变后,由于缺乏纯化选择使它消亡,所以由于随机的遗传漂变,出现突变体的频率可能提高,并固定在某一物种中。
- 在小群体中,遗传漂变是一种更大的力量。在这样一种情况下,两份拷贝中哪一份失活往往是一个随机事件(如果不同拷贝在不同群体中失活,那么这可能造成不同个体之间的不相容性,或最终引起种间差异)。
- case 1 : 两个基因都将变成有机体所需的。
- 当被导入到基因组时,转座因子往往增加拷贝数,但它处于负选择和转座调节机制的检测之中。
突变偏爱性可能引起有机体基因组的高A·T含量:
从胞嘧啶到尿嘧啶,或从5-甲基胞嘧啶到胸腺嘧啶的自发脱氨基作用是常见的突变来源,这促进了从G·C到T·A的转换突变。
- DNA中的尿嘧啶比胸腺嘧啶更易于修复;
- 甲基化胞嘧啶(常见于C·G二联体)不仅是突变热点,而且特别偏向于产生T·A对。
鸟嘌呤氧化成8-氧鸟嘌呤能导致从C·G到A·T的颠换,因为8-氧鸟嘌呤与腺嘌呤配对比与胞嘧啶配对更加稳定。
- 基因转变偏爱性往往增高G·C含量,可能引起部分对抗突变偏爱性。
- 在重组或双链断裂修复过程中,会产生霍利迪连接体,它能形成含有非匹配碱基对的异源双链DNA,而它会以突变链为模板进行修复,这样就产生了基因转变;
- 高重组活性的染色体区域显示了偏向G·C的更多突变,而低重组活性的染色体区域往往显示为A·T富集区。
- 密码子偏爱可能源自偏好特殊序列的适应性机制或基因转变偏爱性。
- 解释1:一种特定密码子在募集某种丰富的RNA时可能更有效率,如翻译速率或准确度比使用其他密码子更高。**
Inexplicable points

- 为什么要设置不完全匹配的挂核苷酸序列?不会导致误匹配吗?
- 预测基因突变
- 不会,24个都匹配的话误匹配概率低;
- 为什么要设置不完全匹配的挂核苷酸序列?不会导致误匹配吗?

- 是说这个有害突变不致死,或者相对不那么有害吗?
成簇与重复(看不懂,先跳过)
Terminology
- cluster :通过某一祖先基因的重复(duplication)和变异(variation)而传递下来的一组基因称为一个基因家族(gene family), 它的成员可以成簇(cluster)排列在一起或散布在不同染色体上(或兼而有之)。
- tandem duplication: 一些序列发生了拷贝的同时仍在一起;
- translocation: 将DNA片段从一条染色体转移到另一条染色体上;
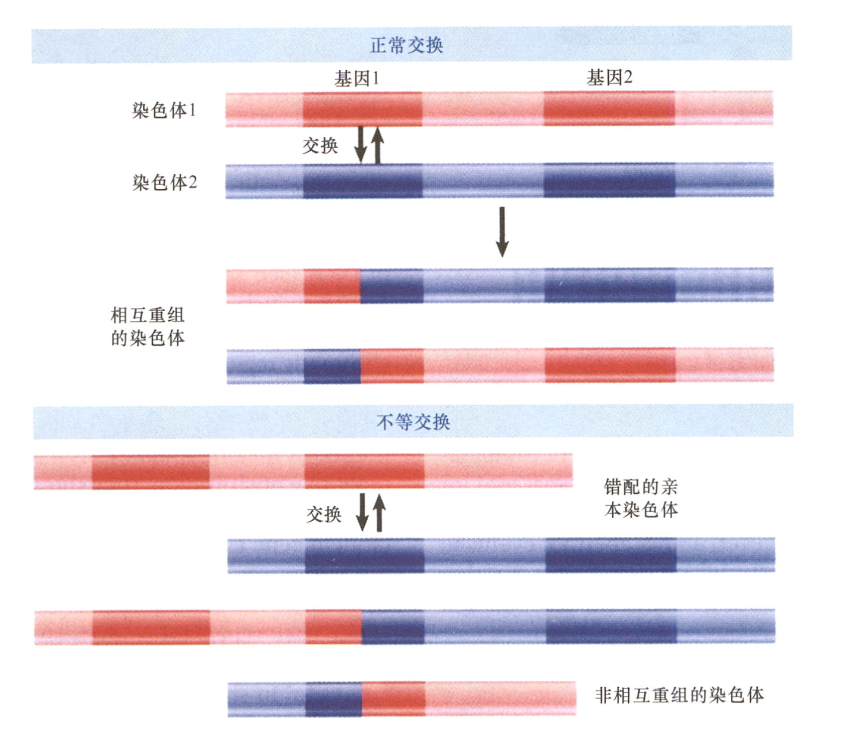
- unequal crossing over: 也称nonreciprocal recombination, 出现在相似或者一样的两个位点之间的重组事件,但是这一重组并不对称,导致一条染色体上的重复拷贝转移到了另一条上;

Key points
- 核糖体RNA(rRNA)是由大量完全相同的基因编码的,这些基因串联重复形成一个或多个基因簇;
- 每一个核糖体DNA(rDNA)簇的组成都是有规律的,转录单位和非转录间隔区交互排列,而每个转录单位主要由rRNA和连接前体组成。
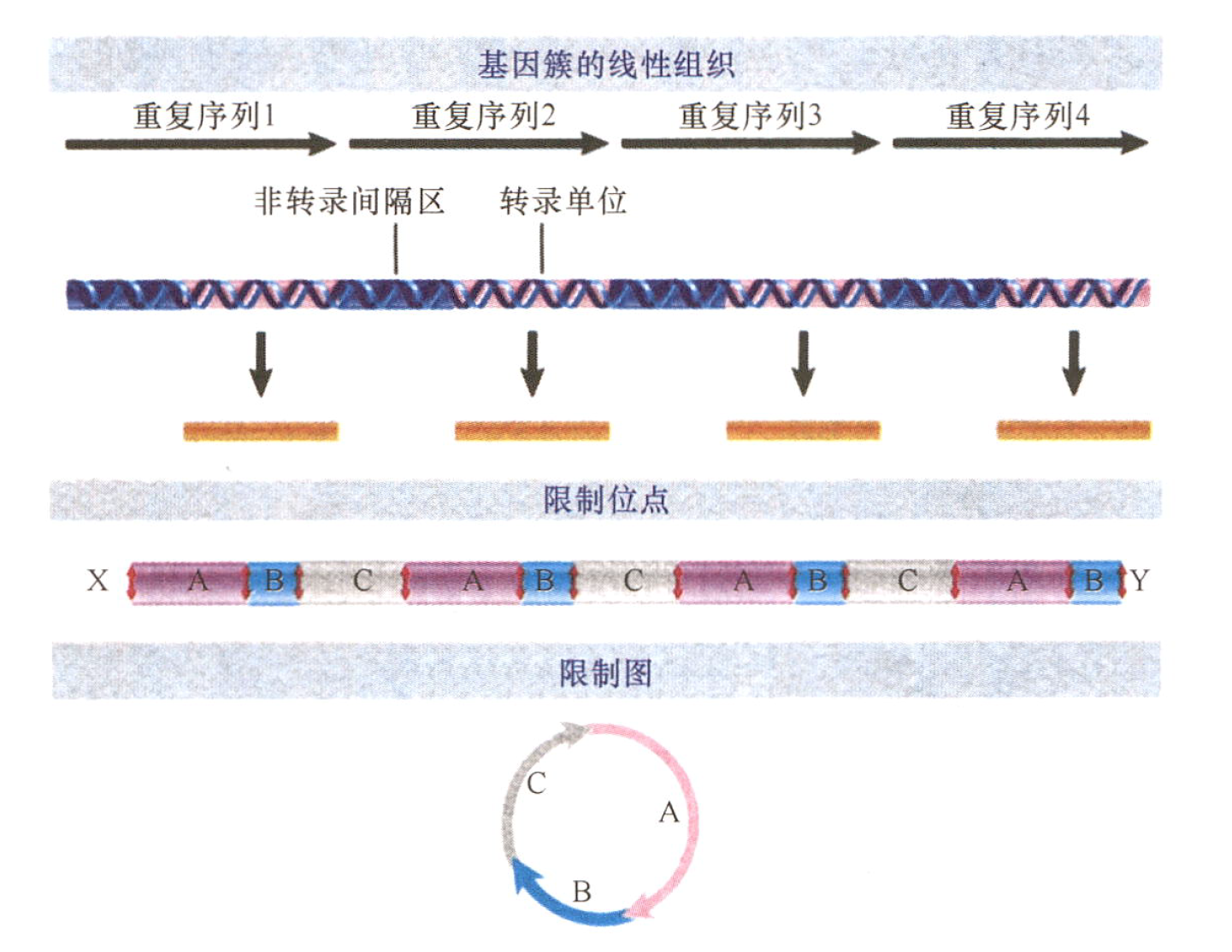
Inexplicable points
- 同源重组的机理是什么?
Chromosome
Terminology
- 包装率(packing ratio): 即DNA的长度除以包装后的长度。
- nucleoid-associated protein: NAP,类似于真核生物染色体蛋白;
Key concepts
病毒capsid包装:
蛋白质外壳沿着核酸组装,在组装过程中利用蛋白质-核酸之间的相互作用来浓缩DNA或RNA。
- 烟草花叶病毒TMV组装起始于RNA的两双链发夹结构,为成核中心;
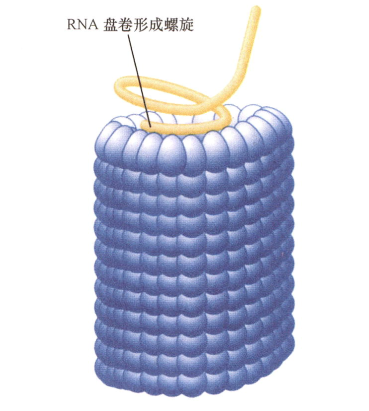
- 每加一层蛋白质亚基,就抓住一段RNA;
衣壳可以被组建成一个中空外壳,核酸在被装进去时,或者在进入的过程中被浓缩。多球状capsid;
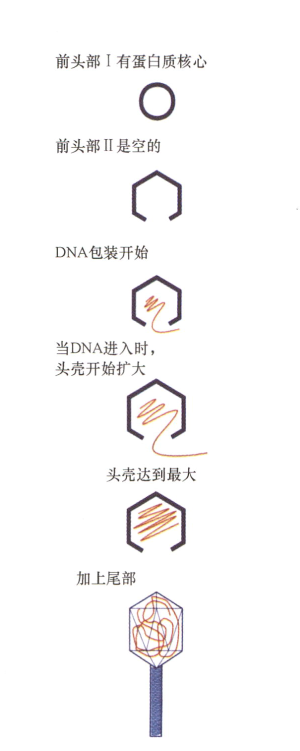
- λ噬菌体成熟过程中,capsid随DNA进入而改变;
将DNA包装进入噬菌体头部包括两类反应:移位和凝聚,这两个过程从能量的角度上讲都是不利的。
- 移位:进行滚环复制后产生长DNA,末端酶(terminase)对其cos site切割产生粘性末端,末端酶接着将其转移到capsid;
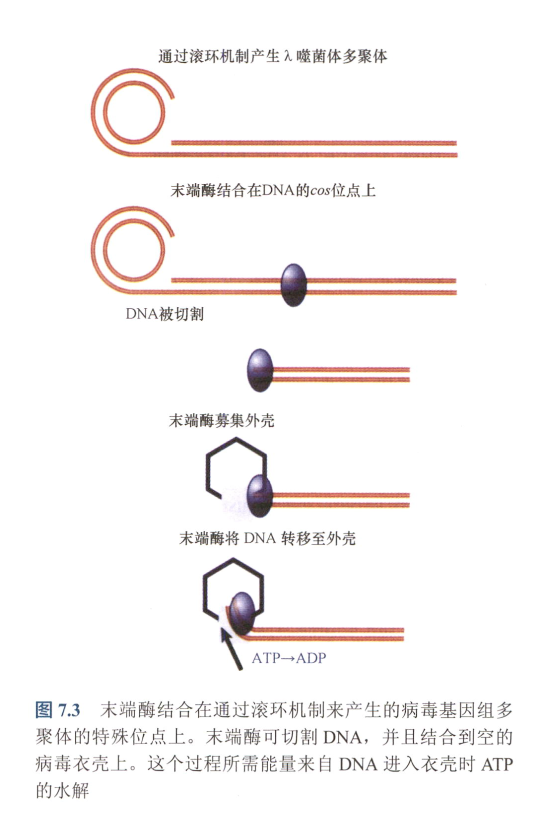
- 移位:进行滚环复制后产生长DNA,末端酶(terminase)对其cos site切割产生粘性末端,末端酶接着将其转移到capsid;
HU蛋白可非特异性地结合与多个位点,但对扭曲的DNA区域具有一定偏爱性;
Inexplicable points
The DNA replication related to Cell circle
Terminology
Key concepts:**
- 细胞周期的起始:
- 假设1:起始子蛋白不断合成,达到一定浓度后,就出发其实反映;
- 假设2:抑制蛋白随着细胞体积的增大浓度稀释到有效浓度以下;
- 细菌一次复制完成(分裂启动)前,另一个复制周期又开始了,从而造成多复制叉染色体(复制得到的子链又形成复制叉);
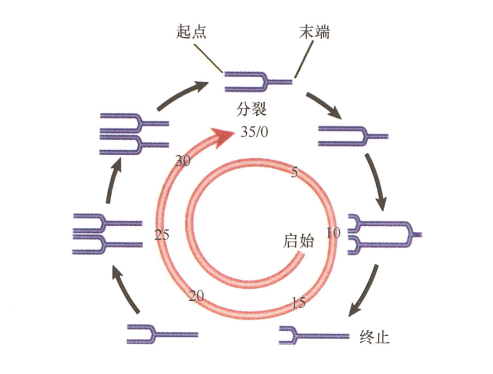
Inexplicable points
The Transpooson and Retrovirus
Terminology
- Insertion sequence: 插入序列,后加数字代表他们被分离的先后顺序。
- 细菌操纵子的自发插入物,其插入阻止了被插入基因的转录和(或)翻译。
- 以末端反向重复序列结尾。两序列密切相关但并非完全一致;
- 这一区域的存在意味着不管朝哪一侧移动,都能遇到相同序列。
- 转座时,插入位点处宿主DNA被复制。
- 该靶序列为复制为同向重复(direct repeat),分布于IS两侧;
- 这一重复序列产生的原因是靶DNA的交错断裂产生粘性末端;
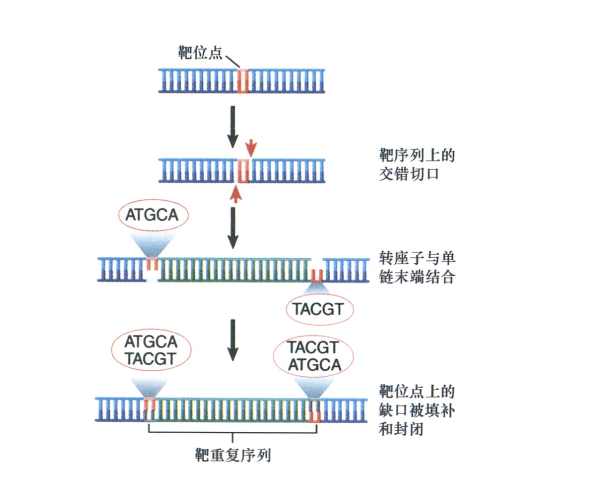
- 末端的顺式作用突变可以阻止转座,这一突变可被负责转座的蛋白,转座酶(transposase)所识别;
- 含有单一长编码区,从一侧反向重复内侧到另一侧之前或其中,负责编码转座酶。
- II类因子:或称DNA型因子。直接操作DNA,并在基因组内自我繁殖。
- I类因子:反转录因子。基于自身的RNA转录物制备出DNA拷贝,再整合进基因组中新位点。
- long terminal repeat(LTR) retrotransposon: 长末端重复反转录转座子,在总体结构和转座机制上,他们和反转录原病毒很相似。
- 也称retrotransposon;
- retroposon:反转录子,同样利用反转录酶,但是没有LTR,有独特转座模式。称为非LTR反转录转座子。
- replicative transposition : 复制型转座, 转座子被重复,转座的实体是原来序列的拷贝;
- 转座酶:在原转座子的末端起作用;
- 解离酶(resolvase):对倍增拷贝起作用;
- precise excision : 转座子发生重组后,细菌酶去掉转座子和重复序列的一份拷贝。
- imprecise excision: 留下转座子的残余序列,阻止靶基因的重新激活;
- 这一切除的频率高于准确切除;
- imprecise excision: 留下转座子的残余序列,阻止靶基因的重新激活;
- cointegrate : 共整合。复制性转座中出现的结构:
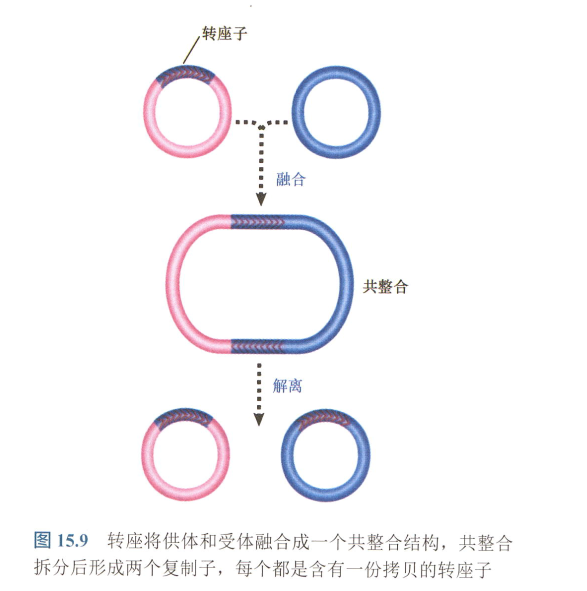
- 链转移复合体的3’端作为复制的引物,产生一个称为共整合(cointegrate)的结构,它由两个原始分子融合而成。
- 共整合结构含有转座子的两份拷贝,每一份拷贝位于两个原始复制子之间的一个连接处,为同向重复序列(不管从哪个方向都是同向)。而转座酶则可使之产生交换反应。它转变成共整合还需要宿主的复制功能。
- 解离过程需要解离酶;
- 链转移复合体:也称交换复合体:
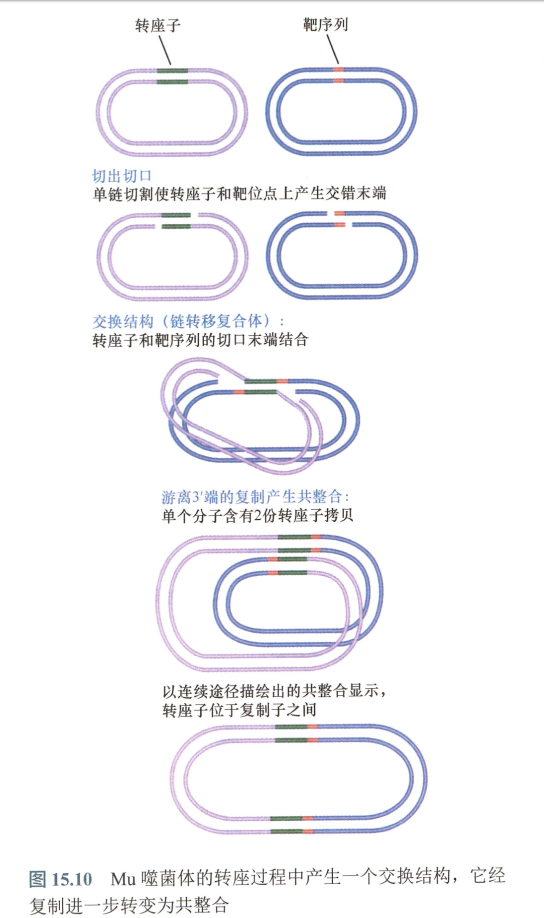
- 交错末端的单链区,是拟复制叉(pseudoreplication fork);
- 自主转座子(autonomous transposon)具有切除和转座能力。
- 非自主转座子(nonautonomous transposon)是稳定的;正常情况下,它们不转座或不允许其他的自发改变。只有在基因组内存在同一家族的自主转座子才能发生转座;
Key concepts
- Ten things you should know about transposable elements
- 必须要RNA中间体参与的转座是真核生物独有的。
- 这一转座必须要运用某些形式的反转录酶。
转座基本反应:
- 转座子的两末端通过酶切反应从供体DNA上分离出来,产生3’羟基(3OH)端。
- 通过转移反应,暴露末端与靶DNA相连接,这个过程涉及转酯作用(transesterification),使3’-OH端直接攻击靶DNA。
- 这些反应发生在一个核酸蛋白复合体内,该复合体包含必需的酶和转座子的两个末端。
- 不同转座子的差别在于靶DNA被转座子识别的时间是否处于其自身被切割的之前或之后,以及转座子的两个末端中一条链或两条链是否在整合前被切割。
当转座子将其另一份拷贝插入原来位点附近的第二个位置时,可能会导致宿主DNA重排,宿主系统可能造成该转座子的两份拷贝之间发生交互重组,其结果取决于其重复序列是同向的还是反向的。
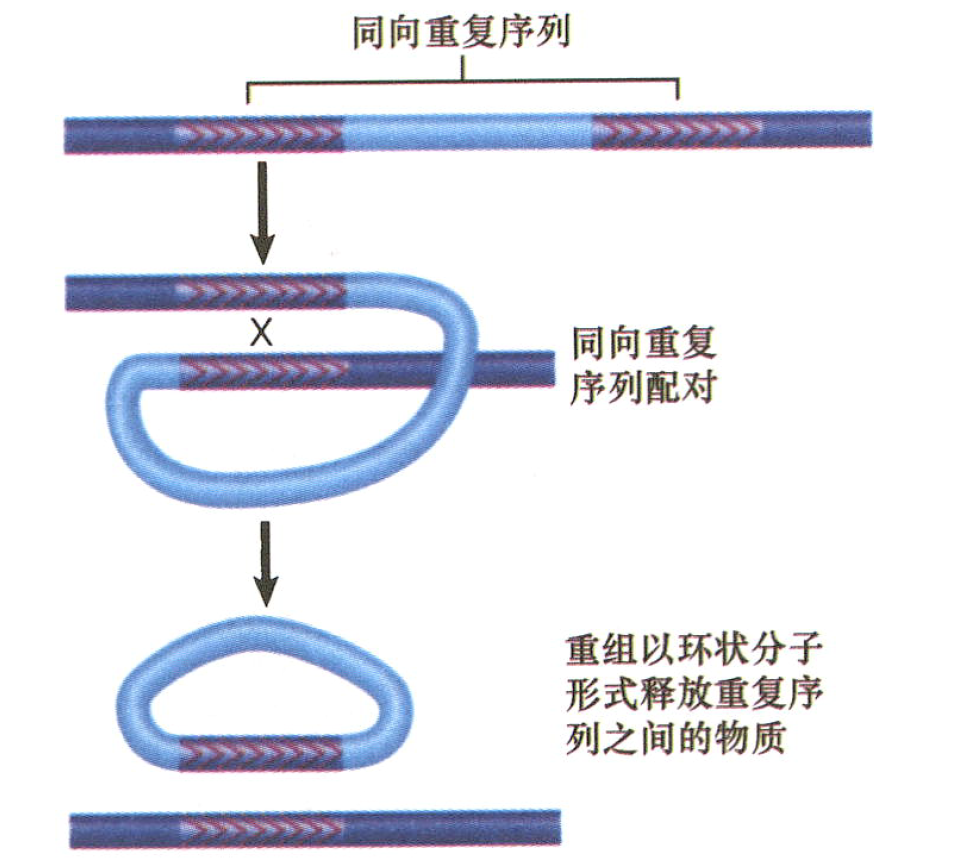
- 两份同向重复序列交互重组会把两者之间的序列切除(以环状DNA形式),包括一份重复序列。
反向重复序列:两个重复序列之间的区域被倒位:重复序列自身还可进一步产生倒位。一个反向的复合转座子是基因组稳定的组件,尽管中心区的方向可能因重组而倒位。
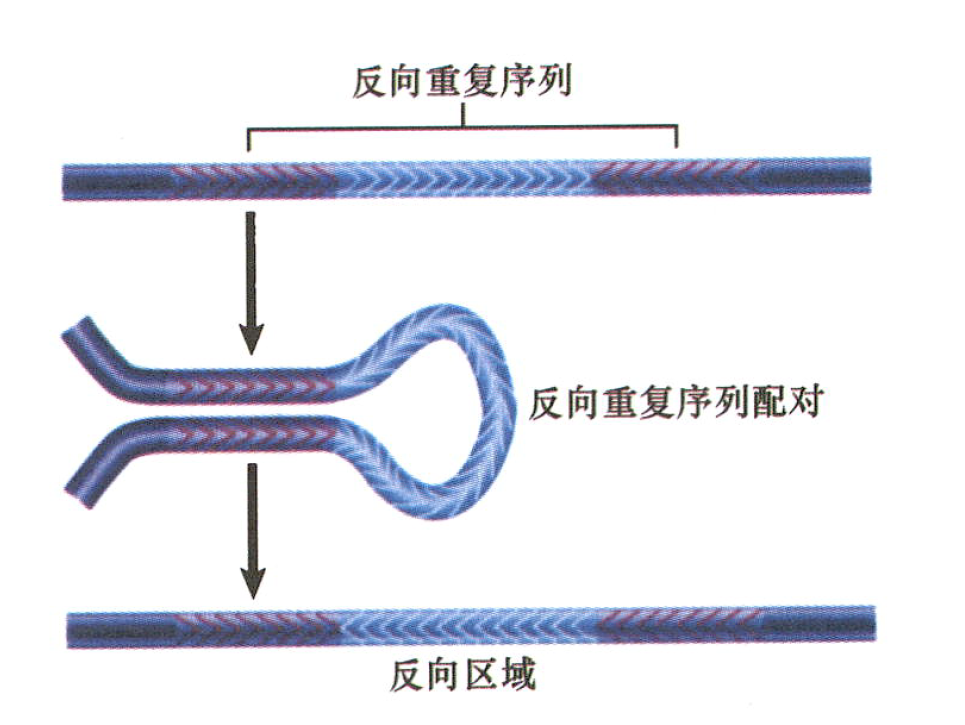
- 两重复序列之间区域可能反向;
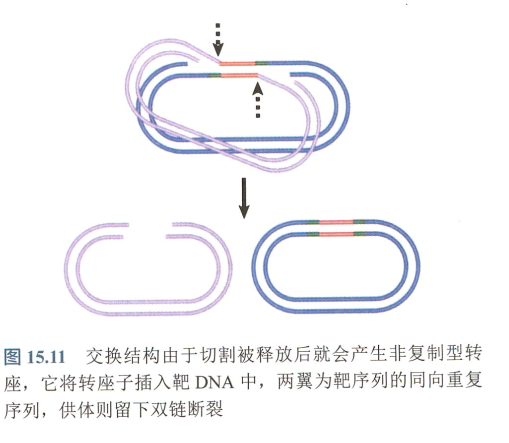
非复制转座的原理:链的断裂和重接
- 靶序列通过插入转座子而重建,供体链仍处于断开状态,不形成共整合结构;
非复制转座:两种形式:
转座子切割过程:
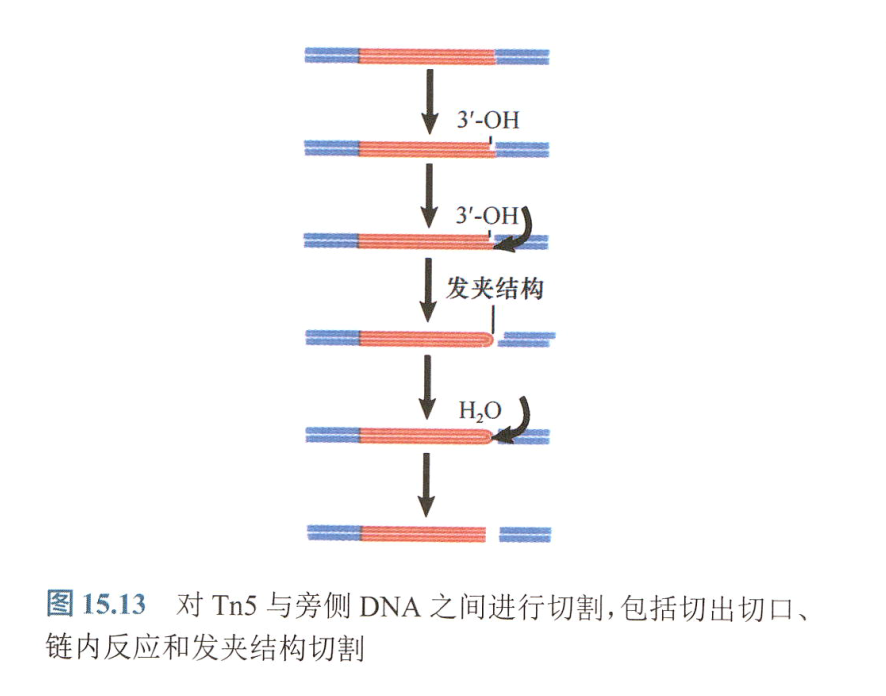
- 切开一条DNA链
- 释放3-OH端攻击另一条链,切割位点5‘侧序列被释放
- 转座子的两条链形成发夹结构
- 激活的H~2~O分子攻击发夹结构
- T10复合转座子:Tn10复合转座子的两条链依次被切断,接着转座子与已切断的靶位点连接起来;
- T5转座子:
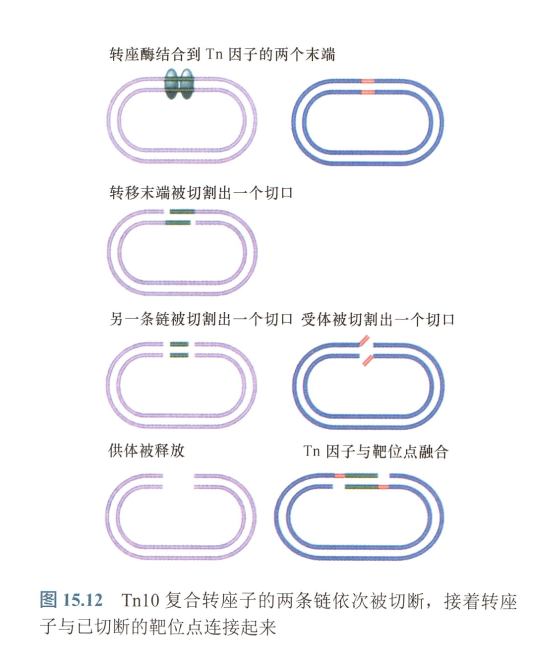
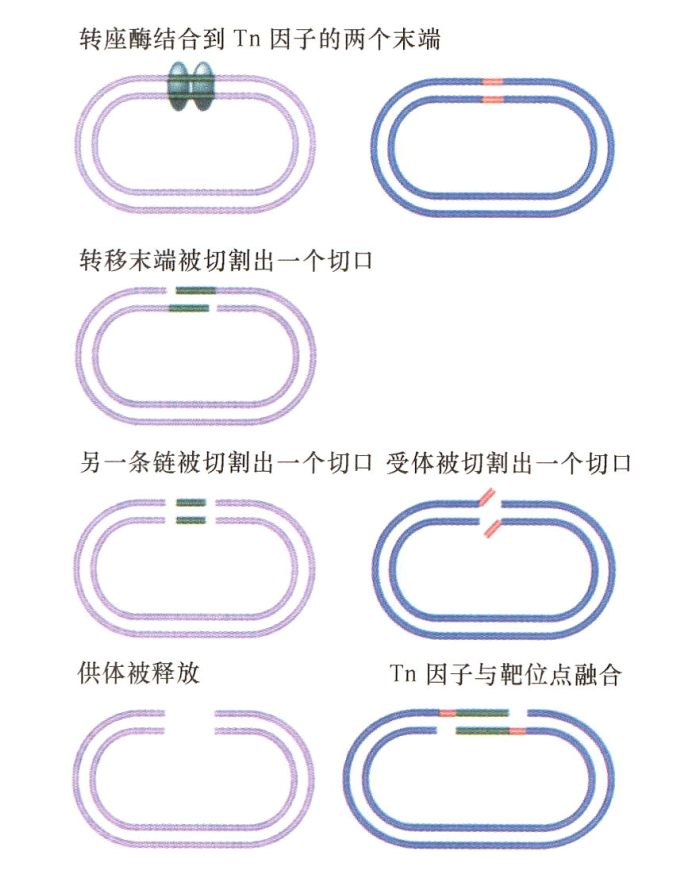
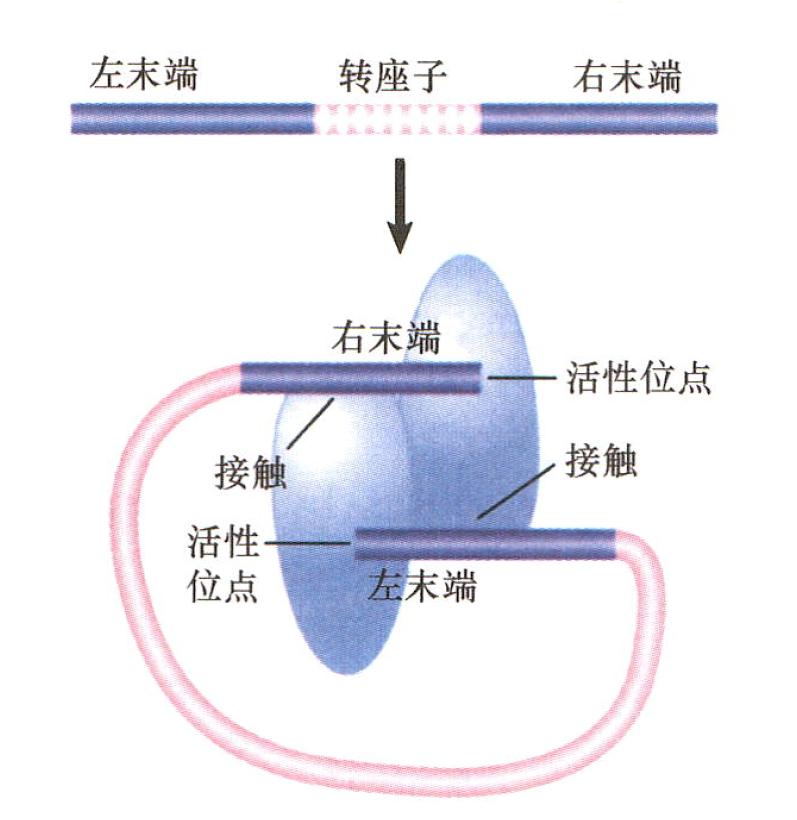
Inexplicable points
Prokaryote transcription
Terminology
- transcription unit: 从启动子到终止子的一段序列;
- 最先转录成RNA的第一个碱基对为转录起点;
- 启动子5‘端序列为上游,3’端序列为下游;
- transcription bubble:转录泡,RNA聚合酶将DNA分开,形成两条暂时的单链。
- 转录泡随着合成,逐渐迁移,其后的DNA重新形成双链;
- unwinding point:解链点,RNA聚合酶在转录泡前端解开双链;
- rewinding point: 再螺旋点,在泡的后端重新聚合;
abortive initiation: 流产起始,任何一个碱基插入后,聚合酶都有释放RNA链的可能性,导致流产起始(abortive initiation)产物的产生。
- 在释放出流产起始产物后,聚合酶又从+1开始合成第一个碱基。
- 流产起始的往复循环常常产生长度为几个碱基的寡核苷酸,有时可多达20nt,直到酶真正成功地离开启动子。
down mutation:大多数细菌启动子的突变可造成相关基因转录物的丢失或是大幅度减少;
- 启动子突变使得转录水平增加的则为上调突变(up mutation);
Key concepts
- 转录发生速度约为40-50bp/s,翻译速度大致相同,约为15 aa/s, 但比DNA复制速度慢得多,约为800bp/s。
- 转录泡长度约为12-14bp,但是RNA-DNA杂合链长度只有8-9bp;
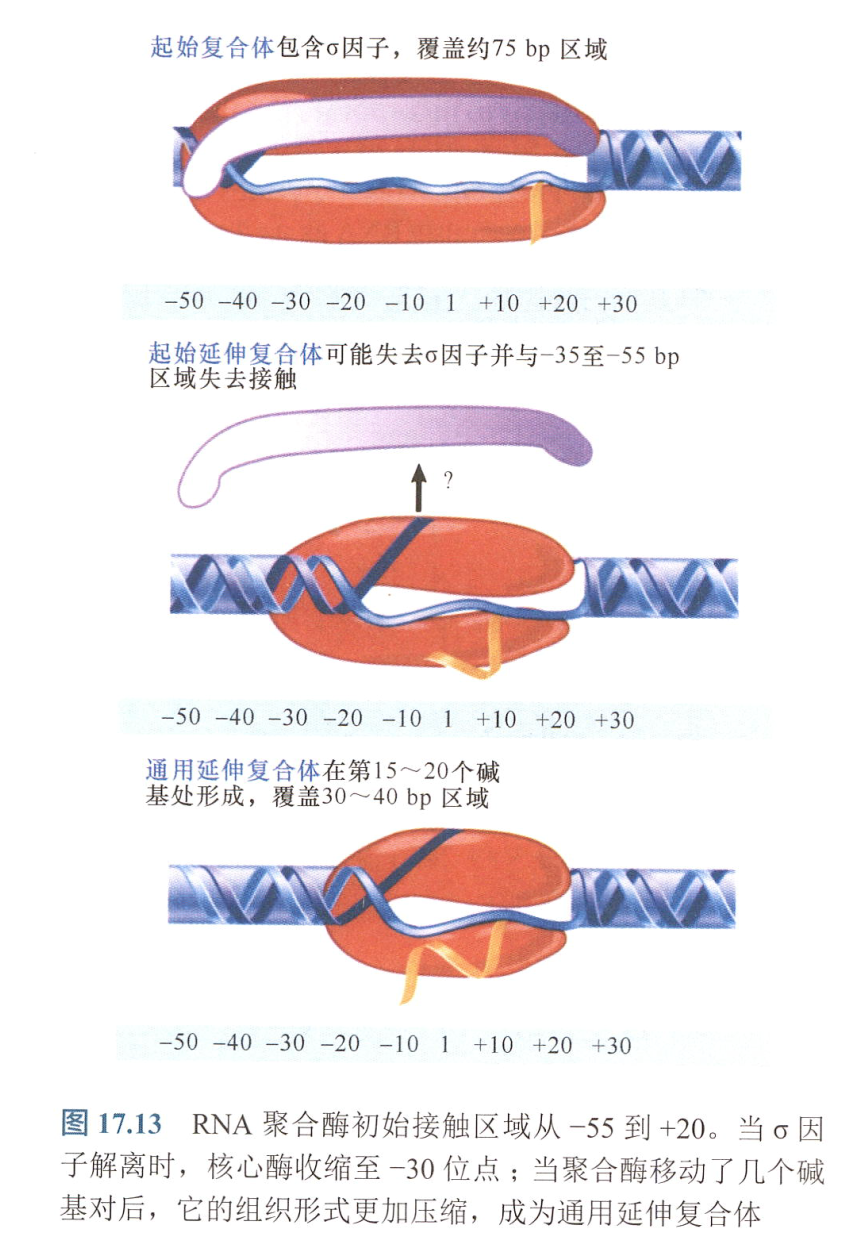
- 在转录的任一时刻,正在生长的RNA链上的最后约14个核苷酸与DNA和(或)酶以复合体的形式存在。
- 转录起始过程:
- RNA聚合酶结合于启动子序列,DNA维持双链,形成closed complex;
- 将DNA双链解开,形成open complex;
- 在细菌中,m/r/tRNA由单一的RNA聚合酶合成,在真核生物中则分别有I/II/III合成;
- 细菌中RNA聚合酶各亚基的功能:
- 两α亚基:负责酶的装配,启动子识别,激活因子识别;
- ββ’亚基:催化中心;
- σ亚基:改变RNA聚合酶与DNA结合的特性,使得对普通DNA序列亲和性降低,对启动子亲和性增高;
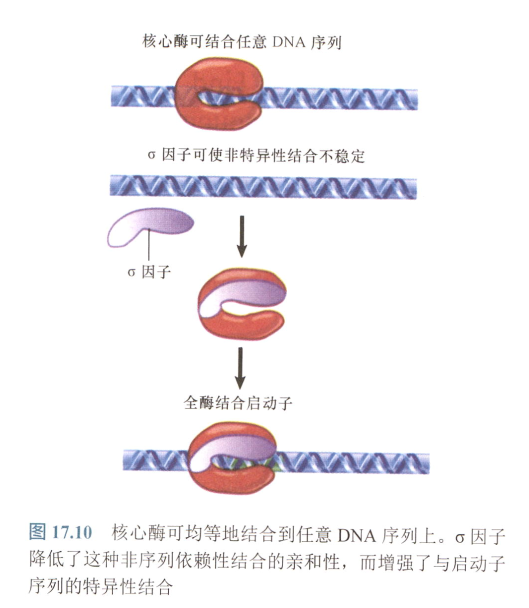
- 核心酶对DNA有均等的亲和力,全酶中结合常数被降低为1/10^4^,与启动子结合常数为10^3^;
- σ亚基在聚合酶合成了近10nt时被释放;
RNA寻找启动子序列方式:
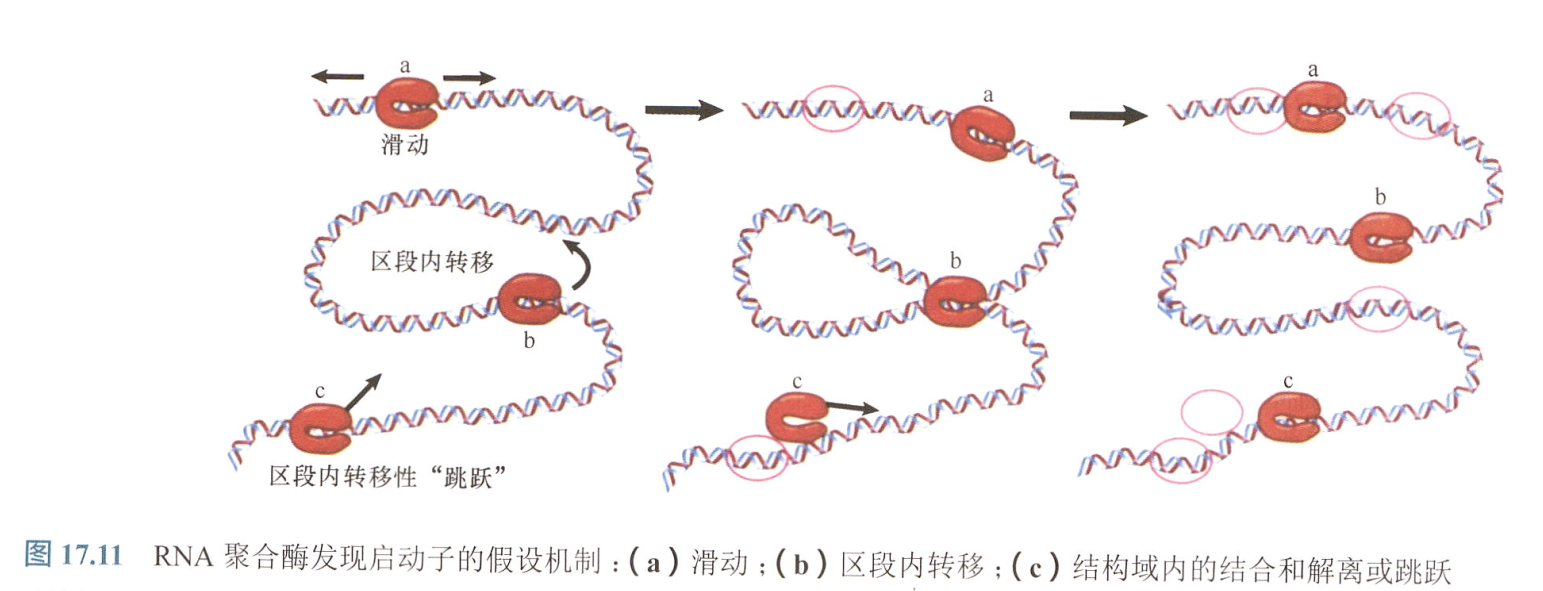
这一假设作用方式为:RNA聚合酶形成和破坏一系列闭合复合体,直至遇到启动子形成开放复合体;
- 这一随机过程,收到速度常数的限制速度过慢,不符合实际,故有其他加速的方式;
第一,酶可能以一维随机步移的方式沿DNA迁移,这称为“滑动(sliding)”。
- 第二,在细菌拟核中存在染色体错综复杂的折叠形式,当酶结合于染色体的某一序列时,酶可能与其他位点靠得很近,这样降低了解离并与另一个位点重新结合的时间,这称为“区段内转移或跳跃(intersegment transfer or hopping)”。
- 第三,当RNA聚合酶非特异性地结合于某一位点时,它能交换DNA位点直到启动子被发现,这称为“直接转移(direct transfer)”。
RNA聚合酶与DNA结合过程中出现的变化:
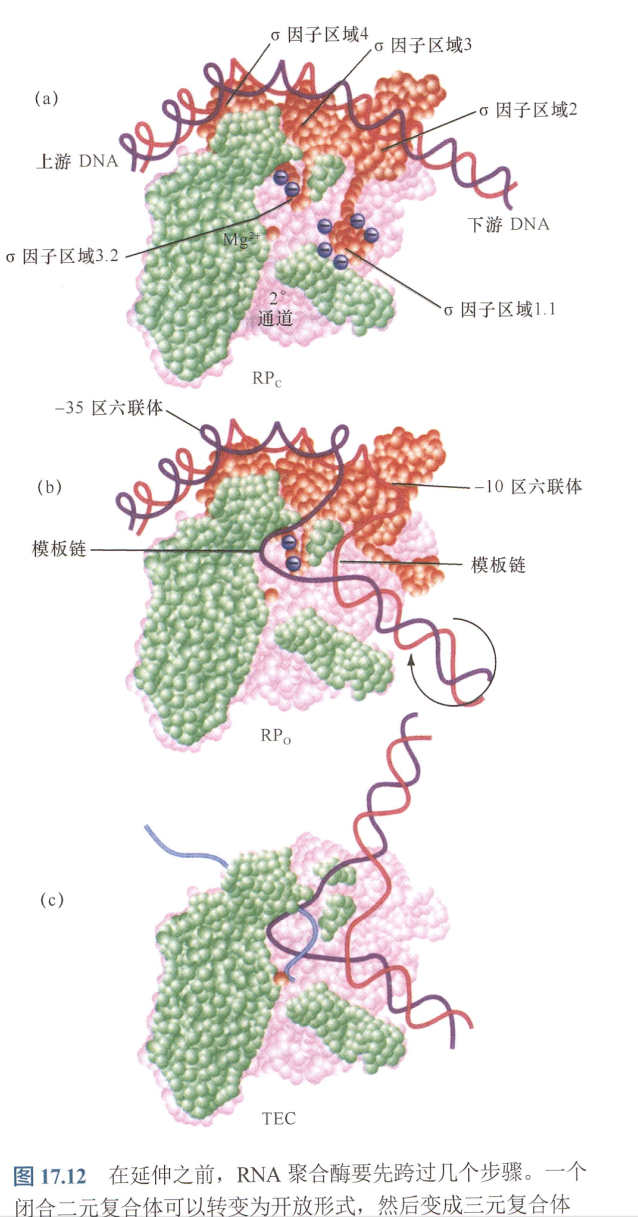
- 注意-35区位置。
- 三元复合体指RNA,DNA,聚合酶;
DNA出现约90°的弯曲,这使得模板能接近于聚合酶的活性位点;
- 在转录起点中,-11到+3之间的启动子DNA的链被打开;
- 将启动子DNA挤入活性通道,形成转录泡;
- 聚合酶的“颌”结构闭合以包围转录起始位点下游的启动子部分。这样,在开放复合体上的启动子接触面就可向外延伸,从-55到+20。
启动子复合体到延伸复合体的转变:
一个启动子是根据在特定位置存在的共有短序列来定义的。
- 对于细菌来说,能够提供足够信号最小长度为12bp,这12bp可以不相邻;
- 随着基因组长度增加,特异性识别所需最小长度也增加;
- 如果碱基数恒定的短序列被某一特定数目的碱基对所隔开,它们若组合到一起,长度可短于12bp,因为所形成的碱基之间的距离本身也提供了部分信息(即使中间序列本身是不相关的)。
在大肠杆菌中,启动子序列缺乏广泛的序列保守性。
- 有一些小段是保守的,只存在很短的共有序列是调节位点的典型特征;
细菌中,启动子最重要的两元件为两6bp元件,-10区和-35区;其次则为-10区,-35区上下游元件;
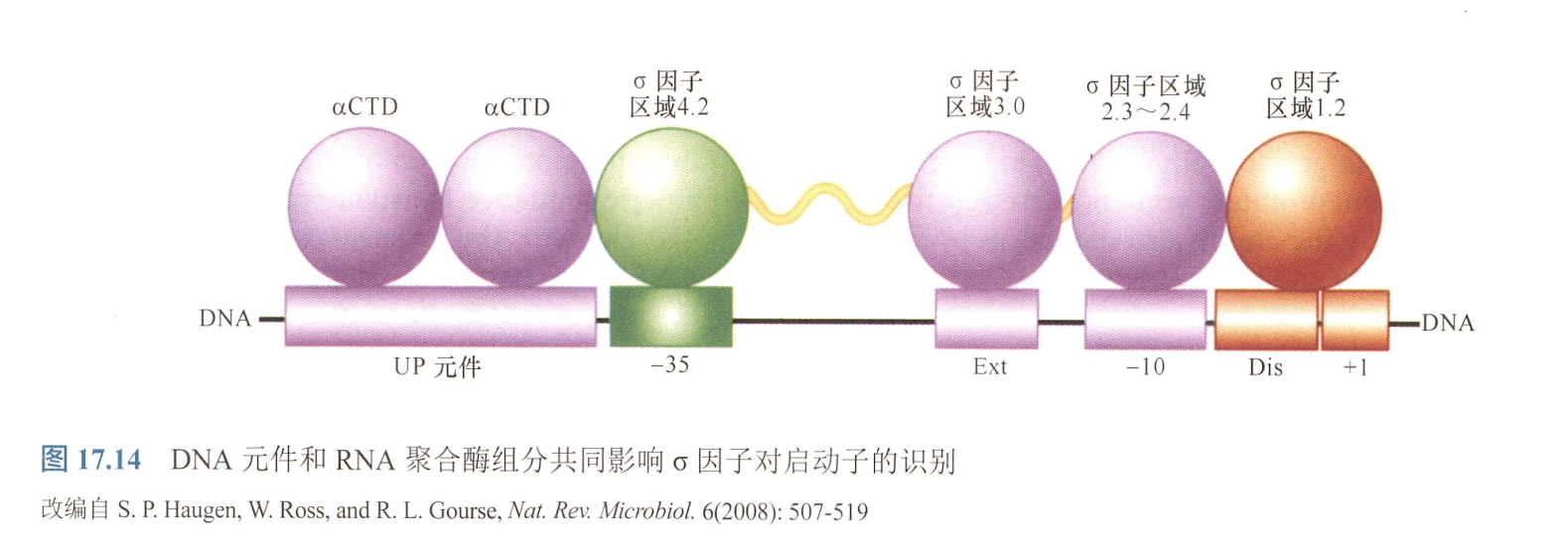
- -10区元件 :别名Pribnow Box,TATA Box(该名称主要用于真核生物中的相似序列);以-10bp处为中心;
- $T{80}A{95}T{45}A{60}A{50}T{96}$, 下标为碱基出现最大频率,对应于其结合重要性;
- 认为-10区中前端高度保守的TA和末尾一个几乎完全保守的T是启动子识别中最重要的碱基;
- 在闭合复合体中为双链,在开放复合体为单链;
- -35区元件:以-35处为中心;
- 在闭合和开放复合体中是相似的;
- $T{82}T{84}G{78}A{65}C{54}A{45}$;
- 间隔区序列:长度约为16-18bp;
- 真实序列不重要,但是距离很重要;
- 因为DNA螺旋的本性是与生俱来的,所以它不仅决定了RNA聚合酶中相互作用的两个区域的恰当分开,而且还决定了两个位点彼此之间的空间定向。
- 转录起点:90%都为嘌呤,典型为腺嘌呤;
- 以CAT序列为中心?
- extended -10 elements: 在启动子缺乏-35区但接近共有序列时,其TGN序列能够弥补这一弱匹配;
- discriminator:-10区下游,在-10与起点之间,能够识别σ因子;
- 大小为碱基对;
- UP元件:-35区上游的10-20bp序列。与两个α亚基的CTD区域作用,在一些高表达的基因的序列中,它能够极大地增加转录;
- 只有当它与共有序列非常匹配时才将其称作UP元件;
- -10区元件 :别名Pribnow Box,TATA Box(该名称主要用于真核生物中的相似序列);以-10bp处为中心;
- 上调突变大多是增大了-35区和-10区与共有序列的相似性,或使两个保守六联体之间的距离更接近17bp:
- 而下调突变大多降低了它们与共有序列的相似性,或是使间隔距离大于17bp,而且下调突变倾向于集中在有最高保守度的启动子位置上。
- 与共有序列(12 bp)完美匹配的启动子弱于存在至少一处错配的启动子,这是因为结合过于紧密影响了启动子逃逸;
Inexplicable points
Karyote transcription
Terminology
- 转录因子: 转录起始过程必需的蛋白质中非RNA聚合酶成分的部分;
- 转录因子可以结合DNA,也可以识别别的因子,或者识别RNA聚合酶;
- 核心启动子: 含有所有RNA聚合酶的结合与功能发挥必需的结合位点;
- 双向启动子: 位于两个相邻且转录方向相反的基因之间的一段DNA序列
- TBP: TATA-binding protein, TATA结合蛋白. 三种RNA聚合酶起始转录的必需因子;
Key concepts
- 真核与原核生物转录的差别:
- 原核:发生在DNA模板上;真核:发生在染色质模板上;
- 原核:RNA pol通过σ因子解读DNA序列;真核:不能解读DNA;

- 不同RNA聚合酶功能;
- mRNA是三种主要RNA中丰度最低的一个,约占2-5%;
- RNA聚合酶I:
- 含有一个双向启动子, 且除核心启动子外,还有一个UPE;
- SL1复合体: 与核心启动子结合,含两TBP;
Inexplicable points
Gene expression regulation:
Terminology:
- 顺式作用:顺式作用的概念适用于只以DNA形式起作用的DNA序列,只影响与其直接相连的DNA序列。
- 反式作用:基因是编码可扩散产物的DNA序列,这种产物可以是蛋白质,也可以是RNA。任何基因产物自由扩散至其作用靶标的过程称为反式作用
- negative control:通过阻遏物来抑制基因表达;
- operator:操纵基因, 阻遏物的结合位点;
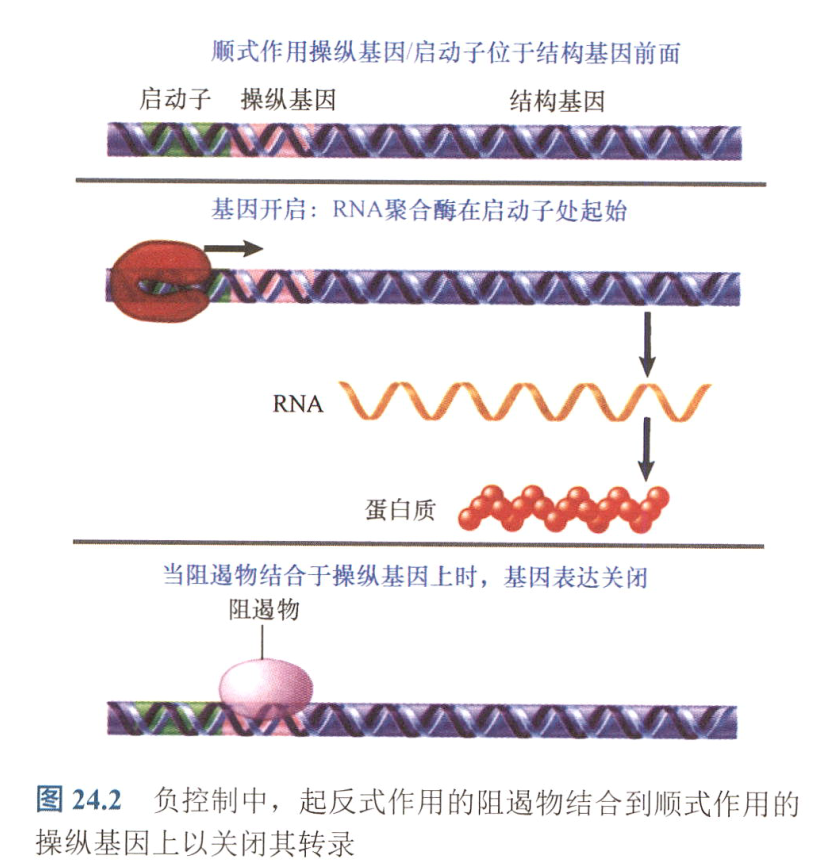
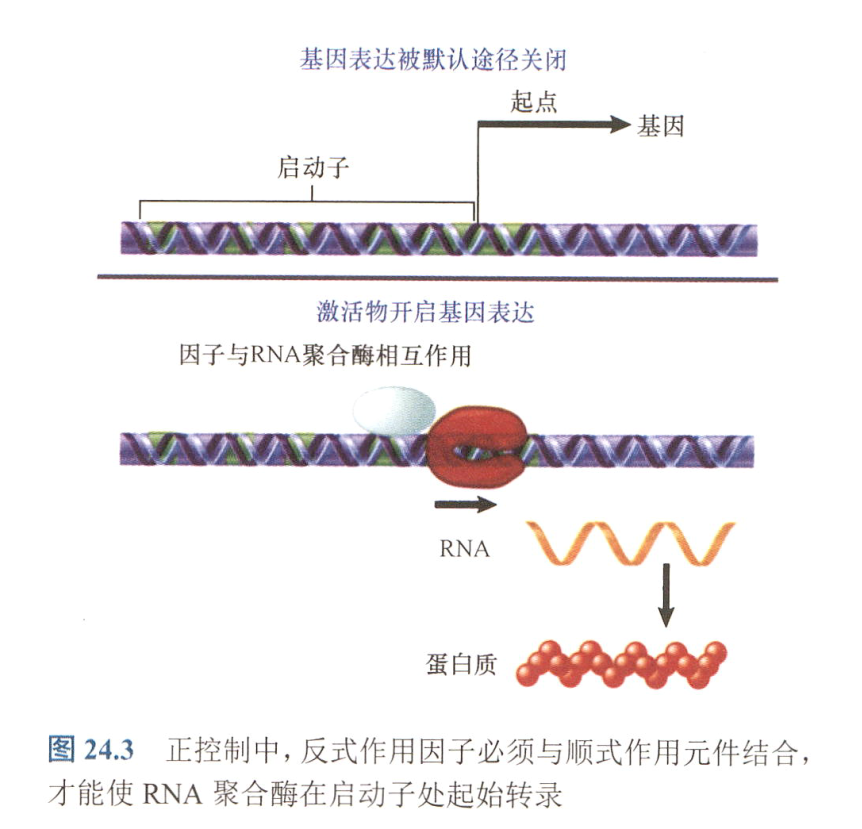
- positive control:通过正调节物来开启基因表达;
- induction:在特殊的代谢物或化合物的作用下,由关闭变为工作状态;
- repression:特殊代谢或者化合物的积累作用下,由工作转变为关闭状态;
- 阻遏不是完全关闭转录,而是将其降低至1/5 or 1/100;
- corepressor:如果某种物质能够阻止细菌产生合成这种物质的酶, 这种物质就是辅阻遏物;
- constitutive expression:表达速率保持恒定的基因表达;
- constitutive mutation:生成可持续表达的基因,也即组成型表达;
- interalletic complementation: 等位基因间互补,阻遏物往往能形成多聚物,从而阻遏物亚基能够随机结合,不论是哪个基因
- 分解代谢物阻遏(catabolite repression):大肠杆菌lac操纵子是负可诱导的。
- 乳糖的存在可以除去lac阻遏物,这样转录就开启了。
- 然而,这一操纵子也受到第二层控制,即细菌如果存在足够的葡萄糖供给,那么乳糖也不能开启这一系统。
- 这一现象的基础是:葡萄糖是一种比乳糖更好的能量来源,所以如果可以获得葡萄糖,那么就没有必要开启lac操纵子。
- autoregulated: 自体调节;
- trpR调节基因受其自身产物tp阻遏物的阻遏。这种阻遏物的作用可降低其合成;
Key concepts:
- 负控制与正控制、可诱导控制与可阻遏控制可以分别组合在一起,形成不同类型的可能调节回路
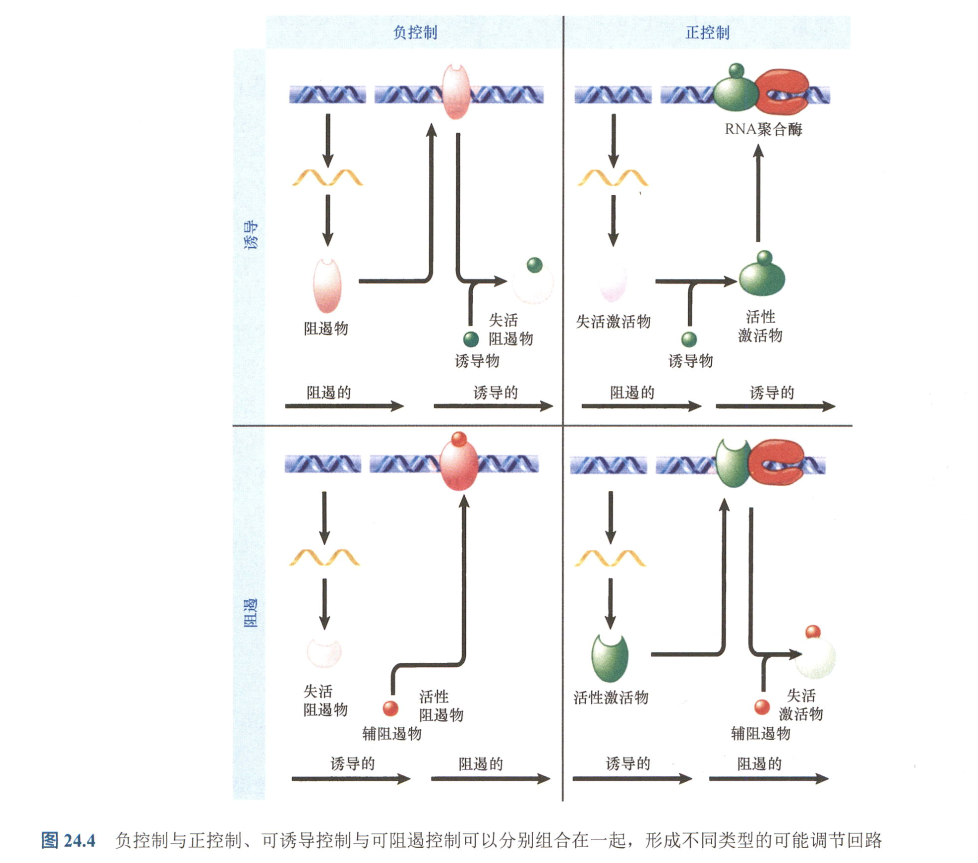
- 负控制+诱导(正控+阻遏):诱导实际上暗示了基因的状态为关闭,负控制说明这一关闭是由于激活的阻遏物引起的,而非失活的激活物引起的;
- 负控+阻遏(正控+诱导):负控和阻遏是一致作用,而负控需要阻遏也即是说原来的阻遏物失活,需要辅阻遏物;
- 元件:
- 负控制元件:阻遏物;
- 诱导元件:诱导物;
- 正控制元件:激活物;
- 阻遏元件:辅阻遏物;
- 原核生物以负调控为主,真核生物以正调控为主。
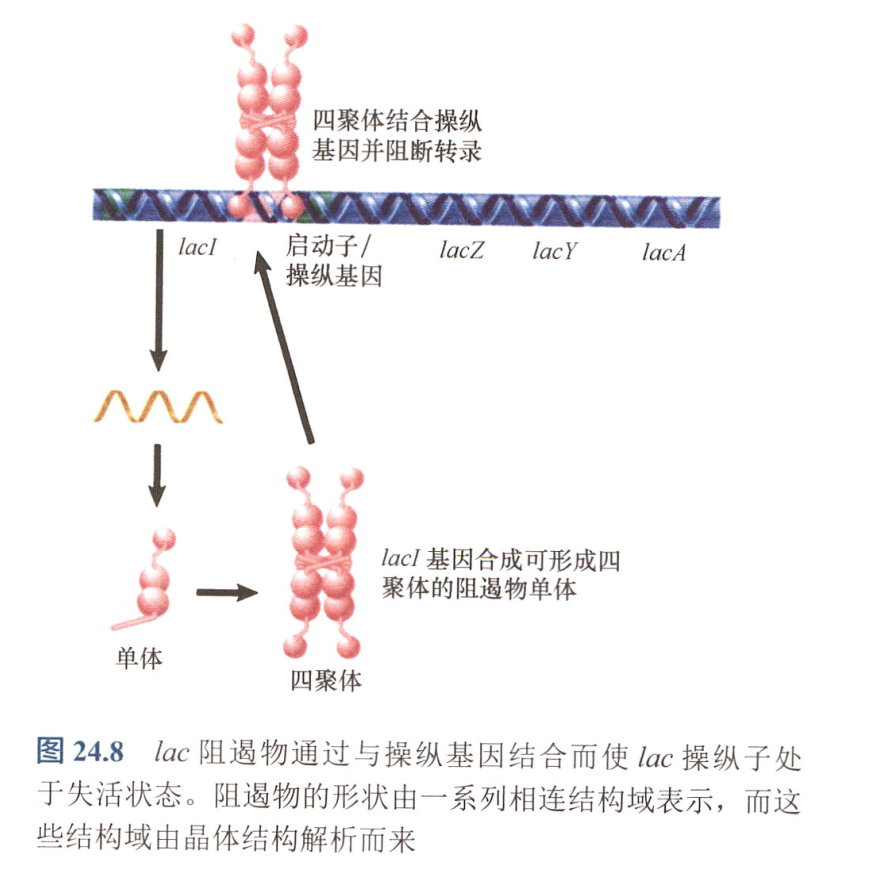
- lac操纵子:
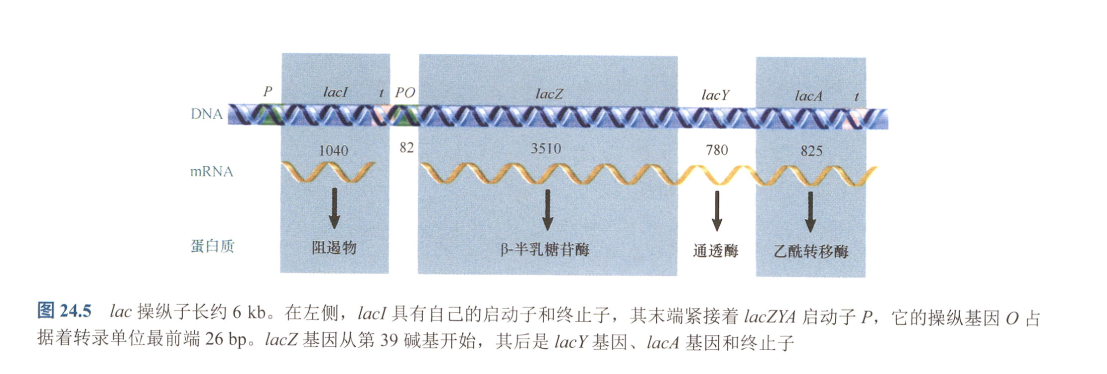
- 由三个基因lacZ、lacY和lacA组成;
- lacZ:编码β-半乳糖苷酶,催化β-半乳糖苷分解单糖;
- lacY:编码β-半乳糖苷通透酶,转运β-半乳糖苷入细胞
- lacA:编码β-半乳糖转乙酰基酶,将乙酰从乙酰辅酶A(Acetyl-CoA)转移到β-半乳糖苷上;(可能是用于排出有害的β-半乳糖苷类似物)
- lacI:编码可扩散产物,阻遏物(蛋白质);
- 其启动子与RNA聚合酶结合效率低,同时由于缺少5’-UTR,起始翻译的能力较低,导致该阻遏物的丰度较低;
- 操纵基因:阻遏物可以与之结合阻止转录,含有反向重复序列(转座子?);
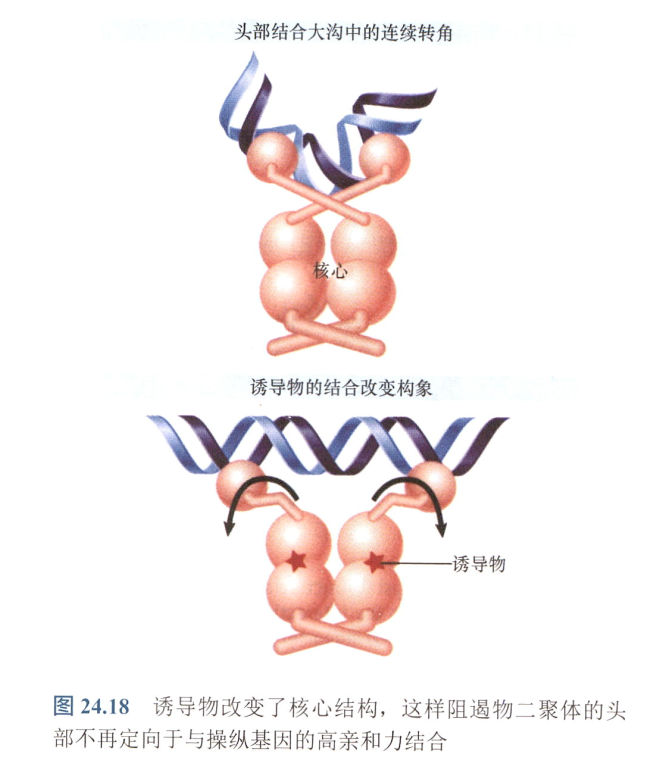
- 阻遏物-操纵基因结合的另个关键元件一铰链螺旋插入到操纵基因DNA的小沟中,这使DNA弯折45°。这种弯曲使大沟可定向用于HTH结合。
- 诱导物和辅阻遏物:往往与底物或产物结构高度相似;
- 对于lac系统来说一个经典的诱导剂就是IPTG,能诱导酶的合成但是不被酶解的分子,也称为安慰诱导物(gratuitous inducer)
- lac阻遏物:
- 诱导物与阻遏物结合,阻遏物形变,失去功能:
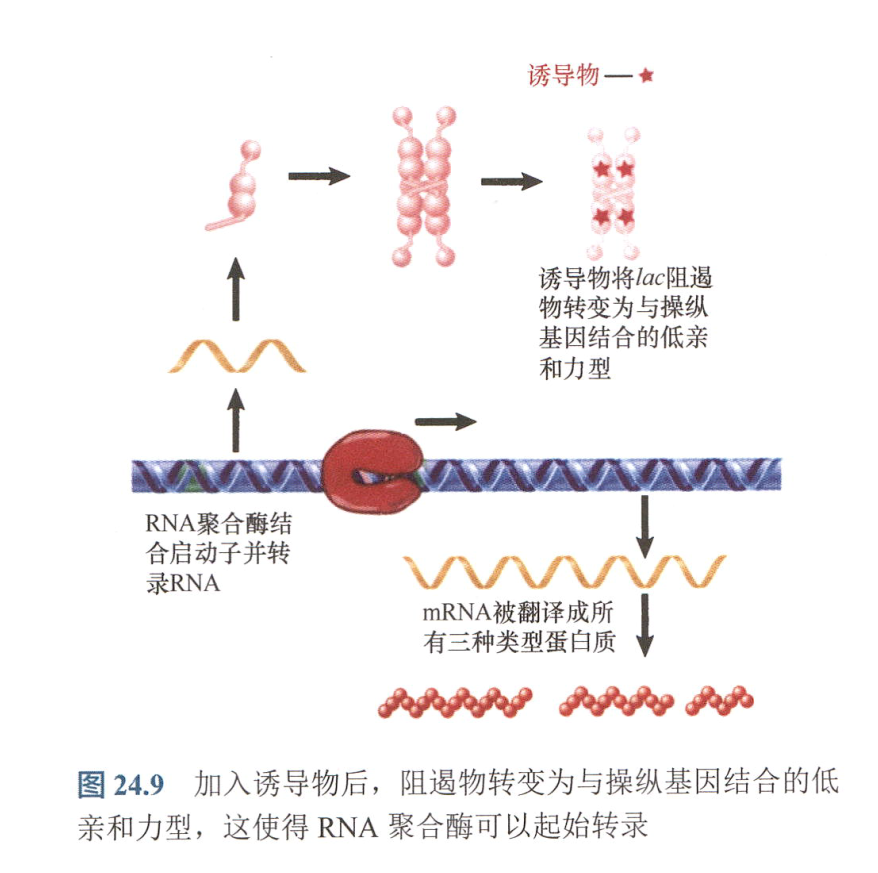
- IPTG改变lacI编码的阻遏物的空间结构,破坏了铰链螺旋,从而使得阻遏物与DNA结合亲和力下降;
- 操纵子的排列:越重要的酶排列越靠前;
- 三种酶的相对数量保持相对恒定;
- 操纵子存在一个基础表达,以相当低的速度转录,从而保证体内存在通透酶,能够将诱导物吸收进体内;
- 操纵基因的鉴定:
- 组成型表达的根源实质上是缺少表达的抑制,从而一直表达;
- 故而组成型表达可分为两类:反式作用(调节基因突变),顺式作用(操纵基因,启动子突变)
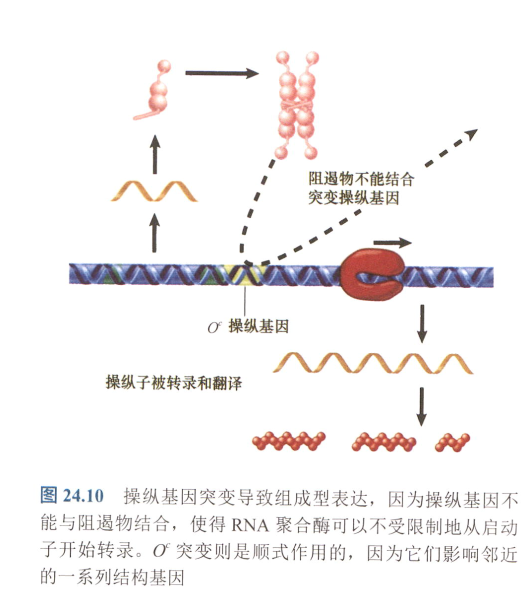
- 顺式显性作用:假设操纵基因突变,另外有别的启动子无法替代;
- 调节基因:
- 反式隐性:$lacI^-$突变,无法结合操纵基因,但只要有别的lac基因能正常表达,即可正常调控操纵子;
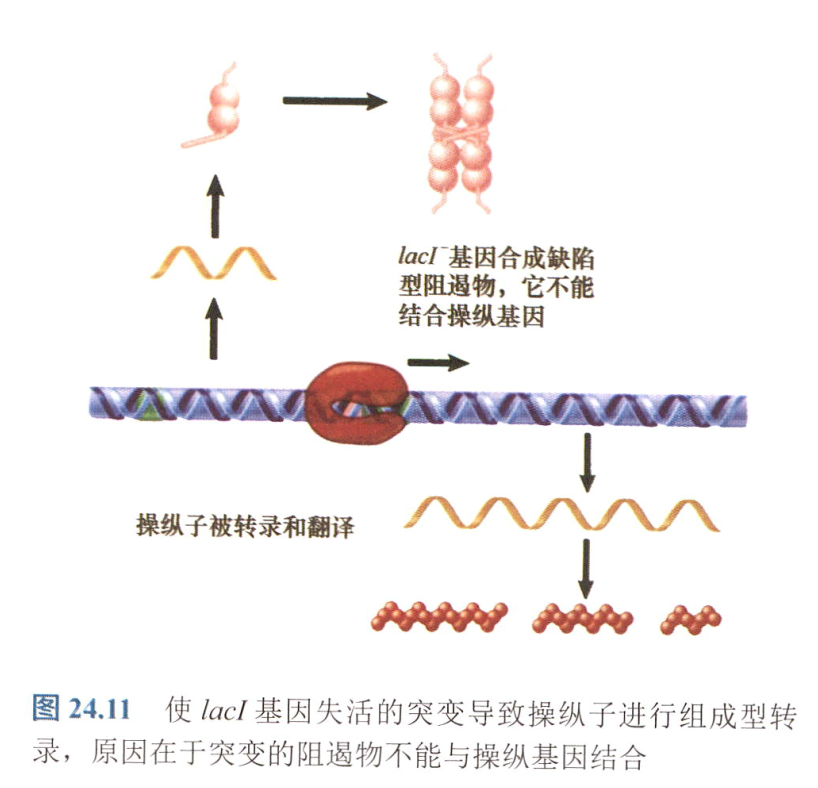
- 反式显性:$lacI^{-d}$突变,DNA结合区域受损;
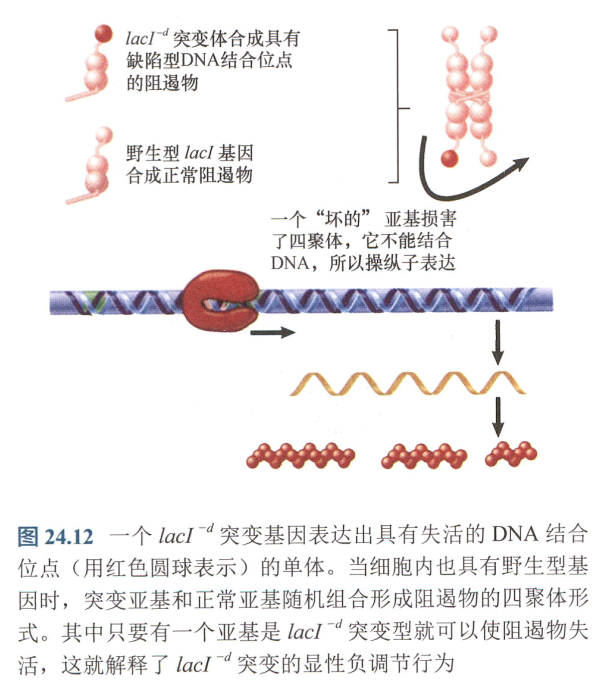
- 反式显性:$lac^{-s}$突变使得阻遏物无法结合或者应答诱导物,产生不可诱导型突变体;
- 反式隐性:$lacI^-$突变,无法结合操纵基因,但只要有别的lac基因能正常表达,即可正常调控操纵子;
- 阻遏物:
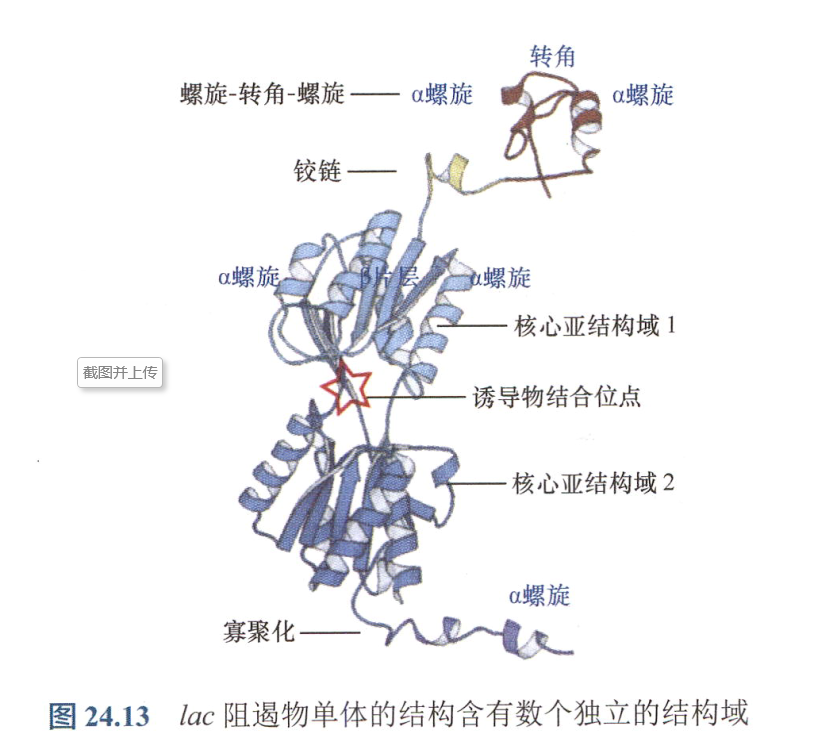
- 末端的螺旋-转角-螺旋是常见的DNA结合基序,
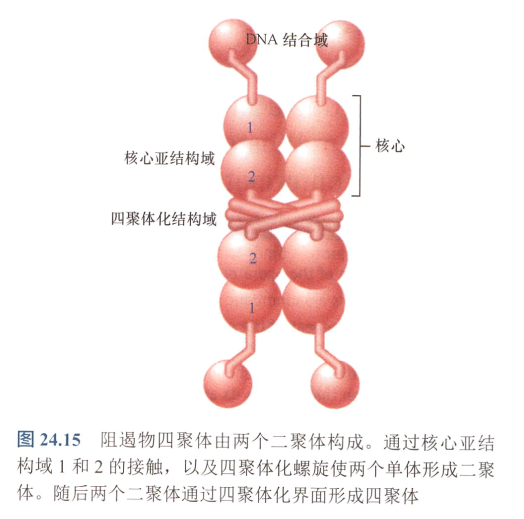
- 所有阻遏物都结合于DNA!
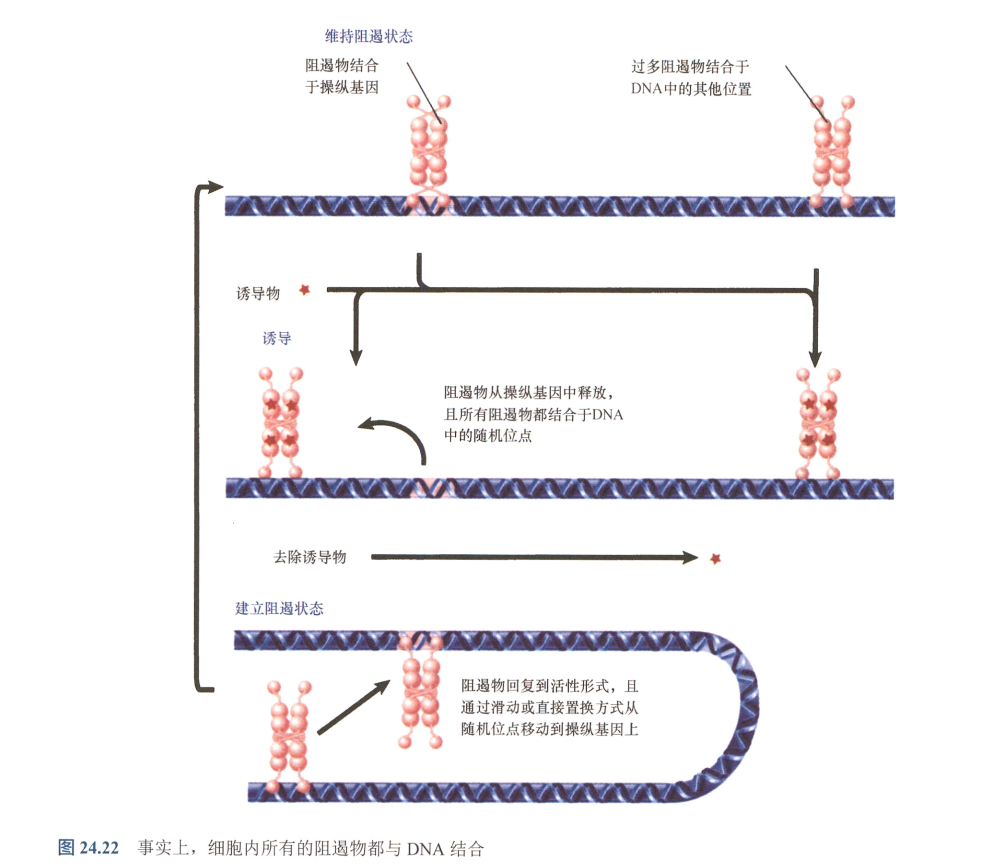
- 阻遏物可以结合非特异性位点,即低亲和力位点,所有碱基对都可以是低亲和力位点;
- lac的分解代谢物阻遏系统:
- CRP:部分启动子转录需要辅助蛋白的参与,即依赖性启动子所必需的,又CRP需要结合cAMP才有活性,形成正控诱导体系;
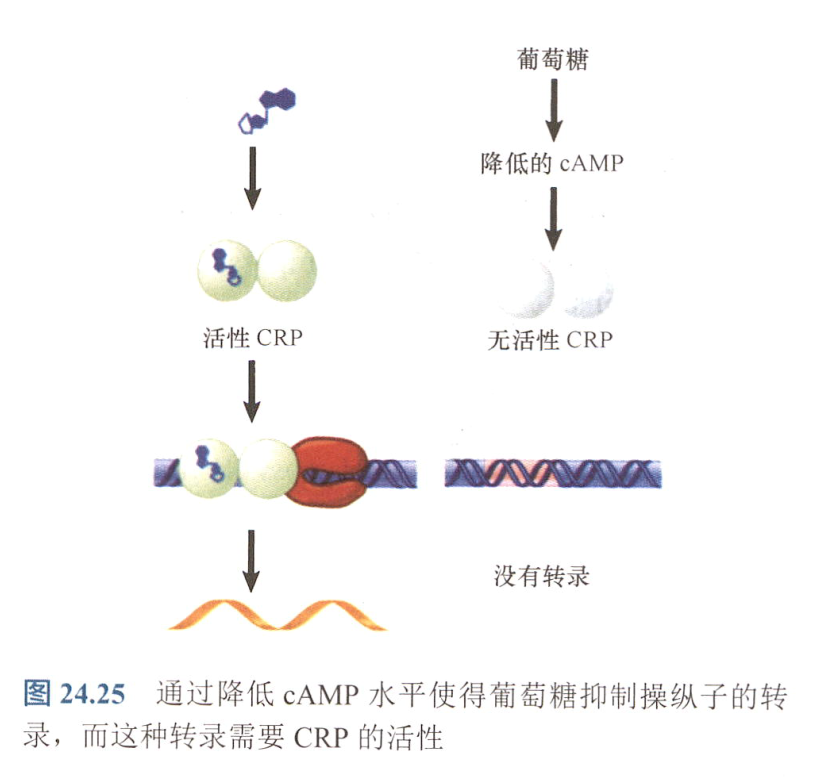
- 又高水平葡萄糖可以阻遏腺苷酸环化酶活性,减少cAMP,使得转录无法激活;
- CRP结构:相同亚基形成的二聚体,被单个cAMP激活,从弱结合变为强结合,且识别特异序列,两个反向五联体序列(两个亚基中心对称);
- CRP能够使得DNA在中心对称处将DNA弯曲90°以上,可能对转录直接作用,也可能只是便于RNA聚合酶结合;
- trp操纵子自身处于负可阻遏控制。这意味着trpR基因产物—阻遏物是以失活负调节物形式制备出来;而阻遏是指rp操纵子产物色氨酸是p阻遏物的辅调节物。
inexplicable points:
- 阻遏物加速诱导?
- 阻遏物与DNA的结合实际上能增强RNA聚合酶结合DNA的能力,只是结合的RNA聚合酶不能起始转录。
- 阻遏物实际上将RNA聚合酶储存于启动子上。加入诱导物后,阻遏物释放,RNA聚合酶能马上起始转录。
真核生物的转录调节:
Terminology
Key concept
- 真核生物中基因表达大多是在转录起始时受开放染色质控制的。
- 许多基因拥有多个启动子,而对启动子的选择可改变调节模式,能影响mRNA的利用,因为会改变5’-UTR;
- 基因表达控制可分为五个节点:
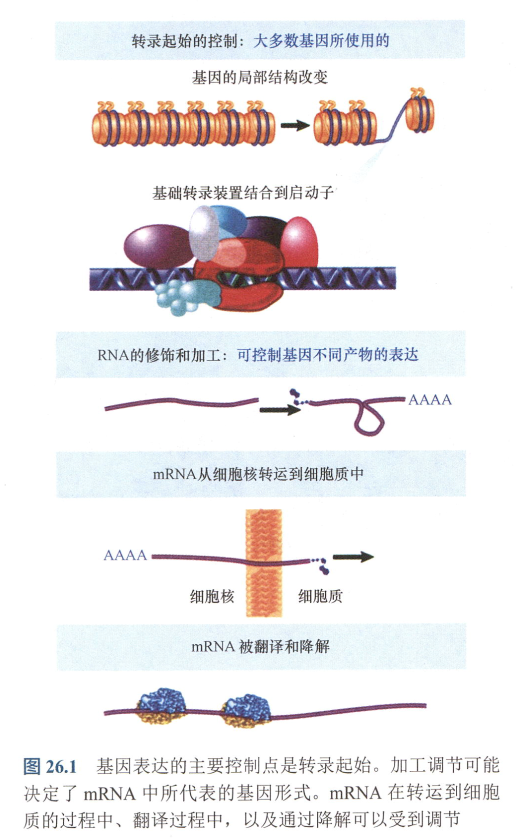
- 转录起始控制
- RNA修饰和加工
- 转运控制
- 翻译过程
- 降解调节
- 基因存在着两种结构状态。
- 第一种是闭合染色质中的非活性基因;
- 第二种是只有在基因表达或潜在表达的细胞里,此时基因处于“活性”状态,或位于开放染色质中。其结构的改变发生在转录开始之前,这表明基因可以被转录的;
- 在单倍体配子中,染色体以高度凝聚,经修饰的染色质状态存在;
- 基因的启动:
- 一些转录因子可能在复制叉之后与组蛋白竞争结合DNA。
- 封闭染色质可能通过暂时性置换组蛋白八聚体从而打开染色质结构
- 如果有机体含有足够高浓度的转录因子,那么染色质可被打开;
- 而如果转录因子浓度较低,那么随后核小体就会结合和凝聚这一区域。
- 一些转录因子可识别“封闭”染色质中的靶标以起始转录。
- 这些转录因子能募集组蛋白修饰蛋白和染色质重塑子;
- 可以开启基因区段,或者是移除启动子结合的障碍物;
- 基因组被边界元件(绝缘子)分成多个结构域。
- 绝缘子可阻断染色质修饰从一个结构域向另一个结构域扩散。
- 一些转录因子可能在复制叉之后与组蛋白竞争结合DNA。
- 真核生物的正控制:
- 真激活物(true activator): 转录因子, 与启动子上基础转录装置发生直接接触发挥功能; 该激活物的调控模式如下:
a. 组织特异性转录因子只在特定细胞类型中合成; 调节发育的因子, 同源异形蛋白(homeoprotein或homeodomainprotein);
b. 转录因子活性可由修饰直接控制(如磷酸化激活);
c. 转录因子可通过配体的结合被激活或失活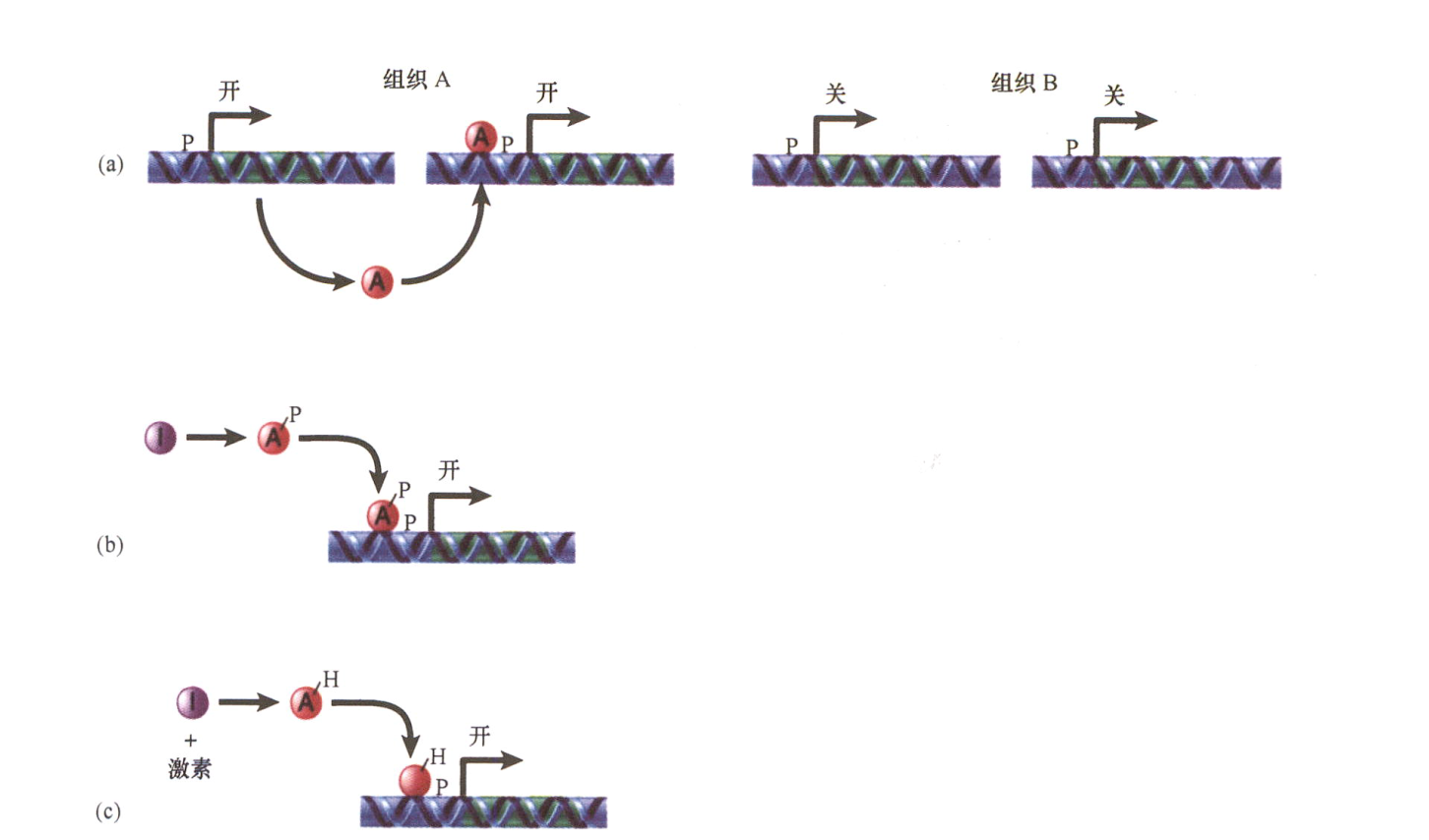
d. 转录因子的有效性可能存在差异
e. 二聚体转录因子可存在不同的配偶体。一种配偶体可使之失活,而活性配偶体的合成可取代失活形式;尤其在螺旋-环-螺旋(helix-loop-helix,HLH)蛋白中
f. 转录因子可从非活性前体中被切割出来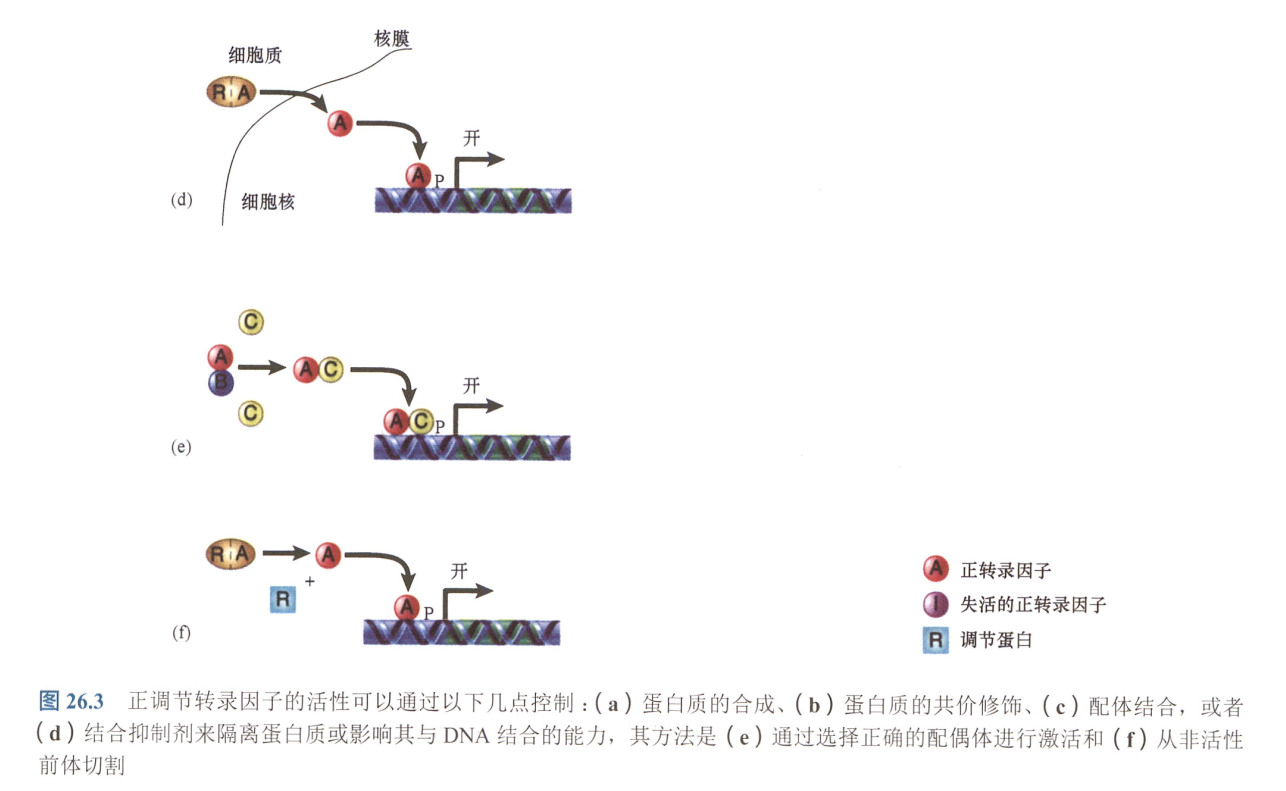
- 抗阻遏物(antirepressor):在这些激活物中,当其中一种结合于增强子时,它会募集组蛋白修饰酶和(或)染色质重塑复合体,将染色质从封闭状态转变成开放状态。
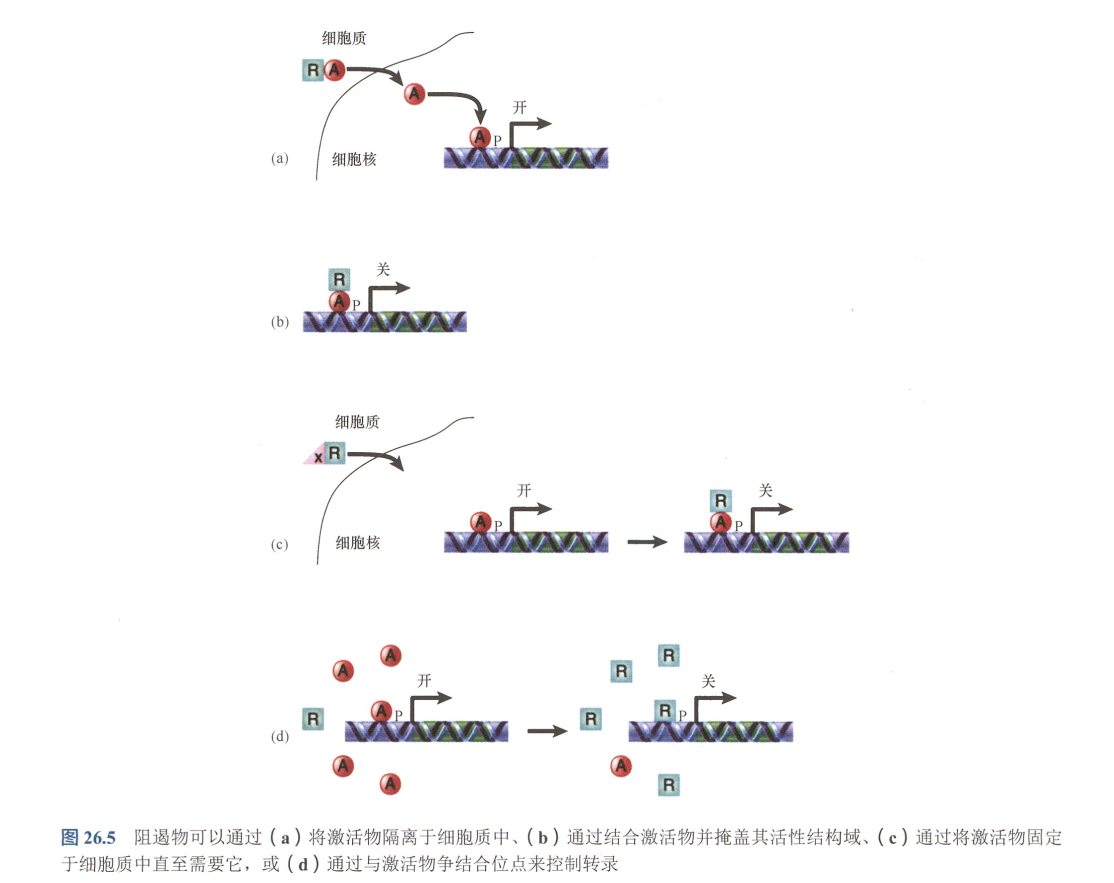
a. 阻遏物将激活物隔离于细胞质中
b. 阻遏物结合与激活物从而使其活性失效
c. 或者阻遏物被掩盖且固定于细胞质, 直到被释放后进入细胞核, 结合激活物
d. 阻遏物与激活物竞争结合位点; - 构筑蛋白(architectural protein,如阴阳(Yin-Yang)蛋白。这些蛋白质的作用是使DNA弯曲,将结合的蛋白质聚集在一起,并形成协同复合体;或使DNA往相反方向弯曲而阻止复合体的形成;
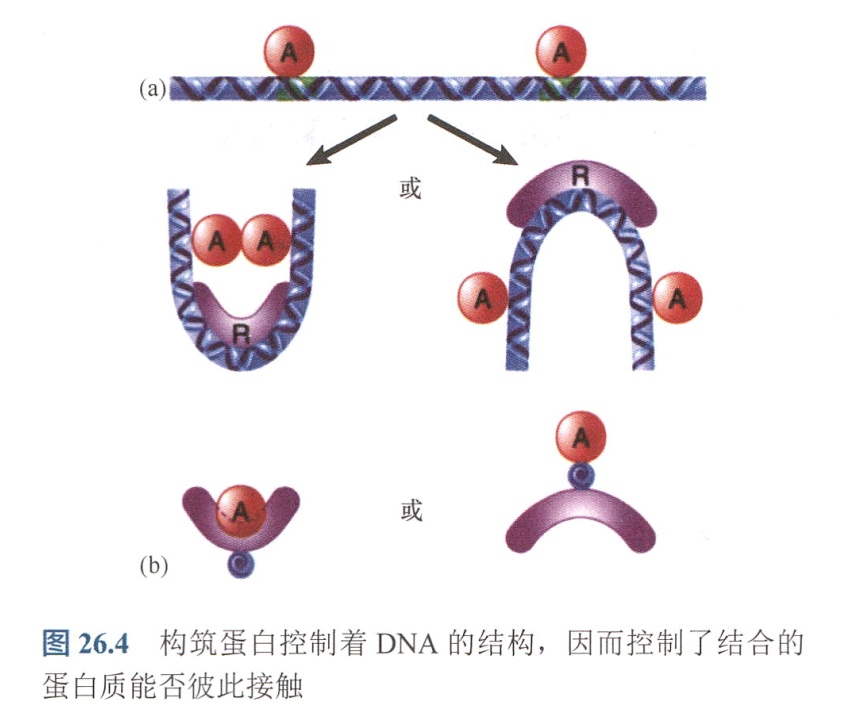
- 真激活物(true activator): 转录因子, 与启动子上基础转录装置发生直接接触发挥功能; 该激活物的调控模式如下:
