
Python爬虫笔记: Javascript逆向分析
Overview
本篇笔记的目的在于记录学习JavaScript逆向的一个过程,由于博主并没有APP逆向的需求,所以仅涉及以下两项:
- 逆向算法:分为能够被解密的算法,对称加密算法(AES,DES等),非对称加密算法(RSA);不能被解密的算法,消息摘要算法(md5,sha),数字签名算法(哈希)。
- 逆向混淆:ob混淆,webpack,jsdom等等
同时本篇内容属于skill learning板块,会主要从实践出发,因而会给出一些案例。
初步了解:一次完整的抓包
这一节我们主要通过http://www.whggzy.com/front/search/category网站来学习进行数据抓包的一个流程。
首先我们进入该网站,并右键->点击检查或者直接敲击F12进入浏览器的开发者工具。

在开发者工具选项中,我们常用栏目有四个:1)元素,这是我们的浏览器实际渲染后的页面。2)控制台,能够与JavaScript进行交互,尤其在我们进入XHR断点时有用。3)源代码,能够查看网站的静态资源,当请求的参数 or 数据 or 标头中有加密内容时,我们需要从这些源代码中找到对应的加密代码,并修改成python形式。4)网络,这一个模块是我们用的最多的模块,我们往往需要通过这一模块查看各个请求的信息。随后,我们随意选取一个条目,通过关键字在网络中筛选出对应链接。
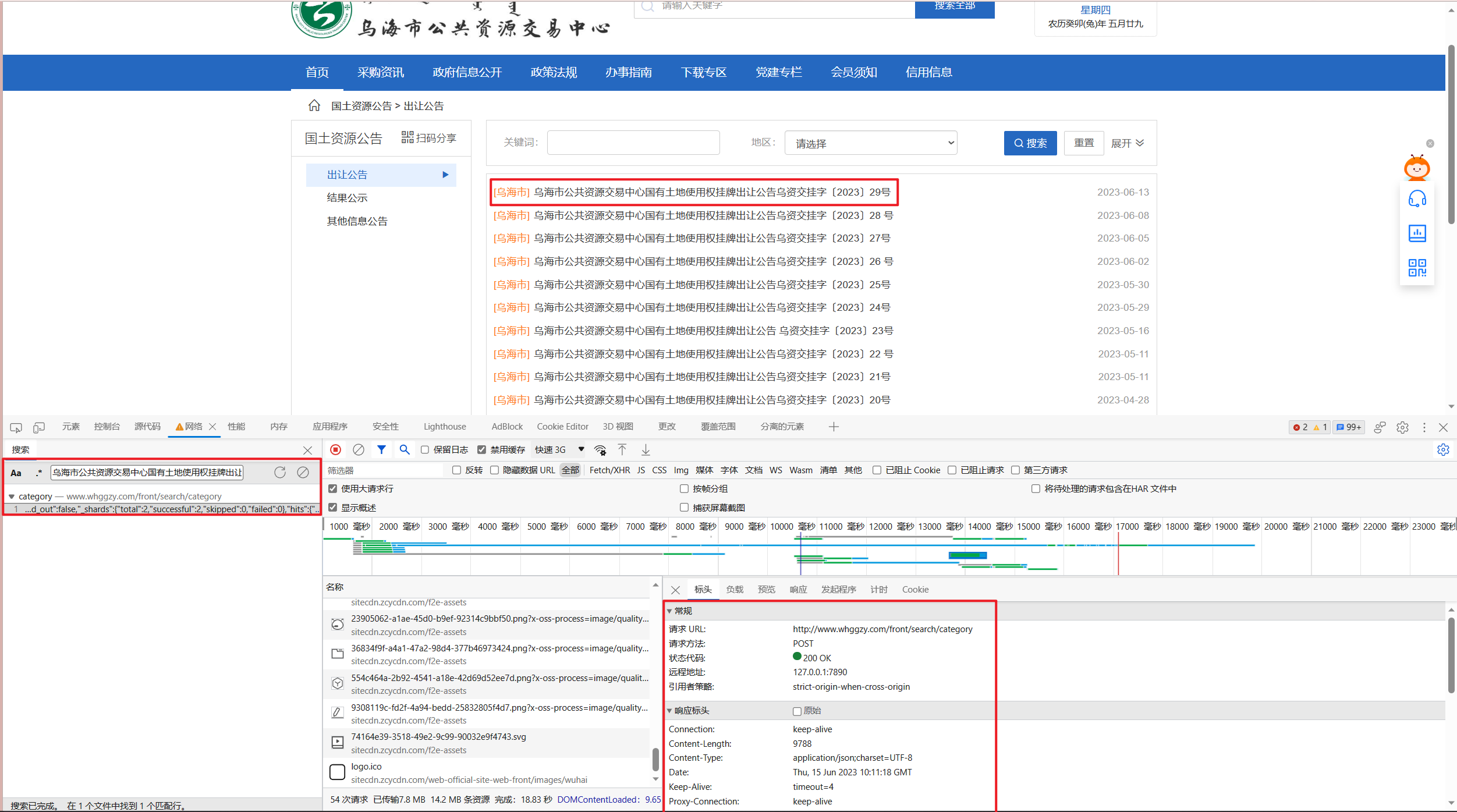
具体步骤为:1)复制关键字,本例中为“乌海市公共资源交易中心国有土地使用权挂牌出让公告乌资交挂字〔2023〕29号”。2)打开开发者工具并定位到网络栏目,ctrl+F打开搜索侧边栏,输入关键字并按下enter,点击出现的条目进入到详情栏。从详情栏目我们可以获得构建一次请求所必须的信息。
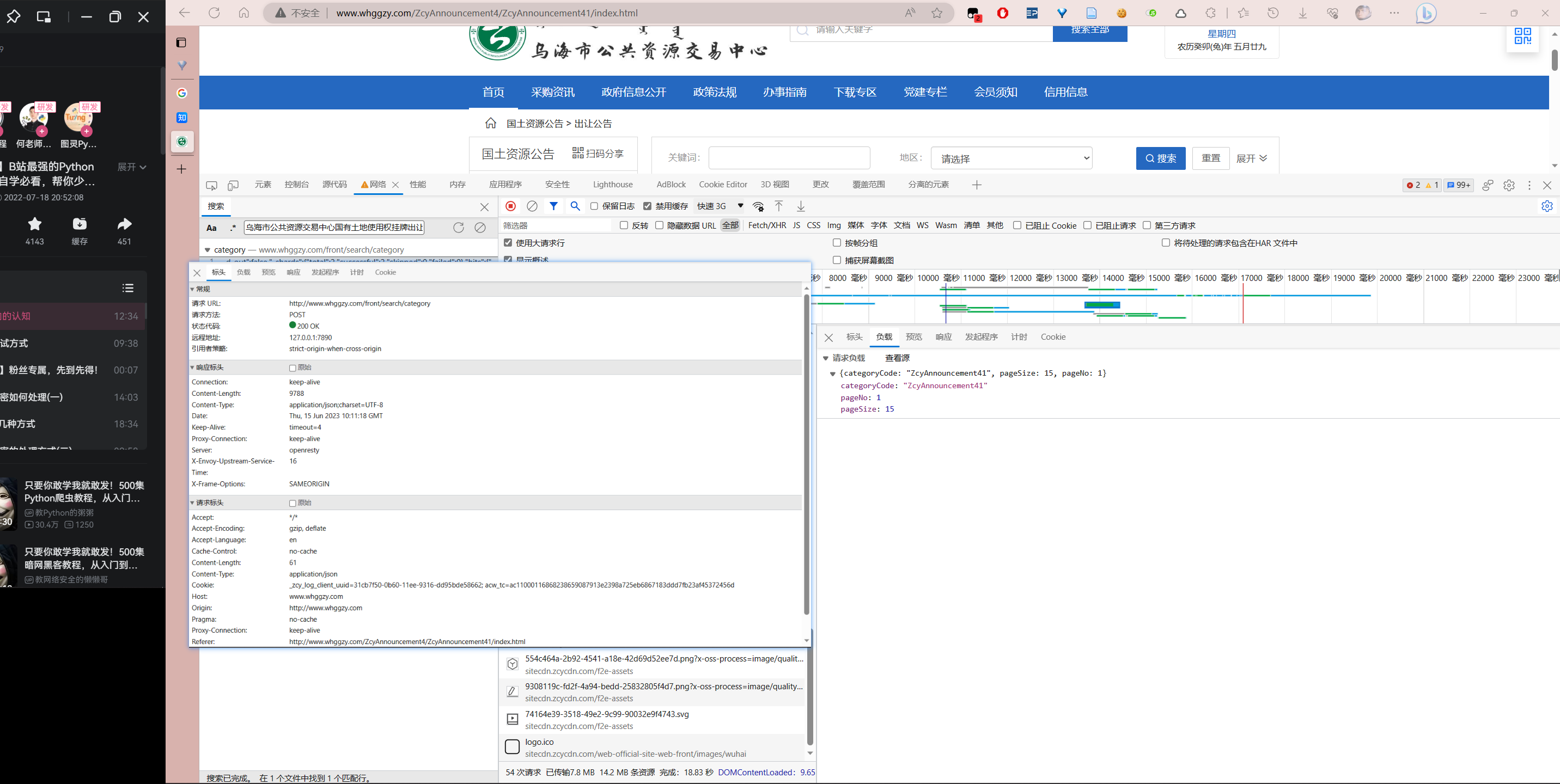
标头栏:1)常规,关键在于请求URL和请求方法, 需要注意的是有的URL由于含有字符串参数,往往显得比较长,我们只需要取前面的部分即可。2)请求标头,在Python中使用字典构建对应的headers从而欺骗网站服务器。
负载:可能分为两类,1)查询字符串参数,即URL 中? 后面# 之前的部分,在requests中使用params参数指定;2)请求负载,即表单数据,使用data参数指定。
预览:查看服务端对本次请求返回的结果。
从上述信息中,我们可以在Python中构建出这一请求,其中headers中的主机地址(host),域名(origin),防盗链接(referer),浏览器类型(User-Agent)是最基本的标头,几乎必填。1
2
3
4
5
6
7
8
9
10
11
12
13import requests
url = "http://www.whggzy.com/front/search/category"
data = {"categoryCode": "ZcyAnnouncement41", "pageSize": 15, "pageNo": 1}
headers = {
"Host": "www.whggzy.com",
"Origin": "http://www.whggzy.com",
"Referer": "http://www.whggzy.com/ZcyAnnouncement4/ZcyAnnouncement41/index.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.43"
}
session = requests.session()
response = session.post(url=url, data=data, headers=headers)
response.text
#$ '系统出错,请稍后重试'
Oops!但是结果为什么会出错?1
2response.status_code
#$ 500
状态码500——表示服务器端错误,然而我们的网页正常渲染了?这说明我们的请求没有能够通过验证。这就要求我们对请求进行调试。
如何调试?我们首先将
front/search/category这一个URL相对地址复制,进入源代码页面,找到右侧边栏中的”XHR/提取断点”, 点击右侧加号添加一个断点,并将相对地址粘贴,接着刷新页面即可。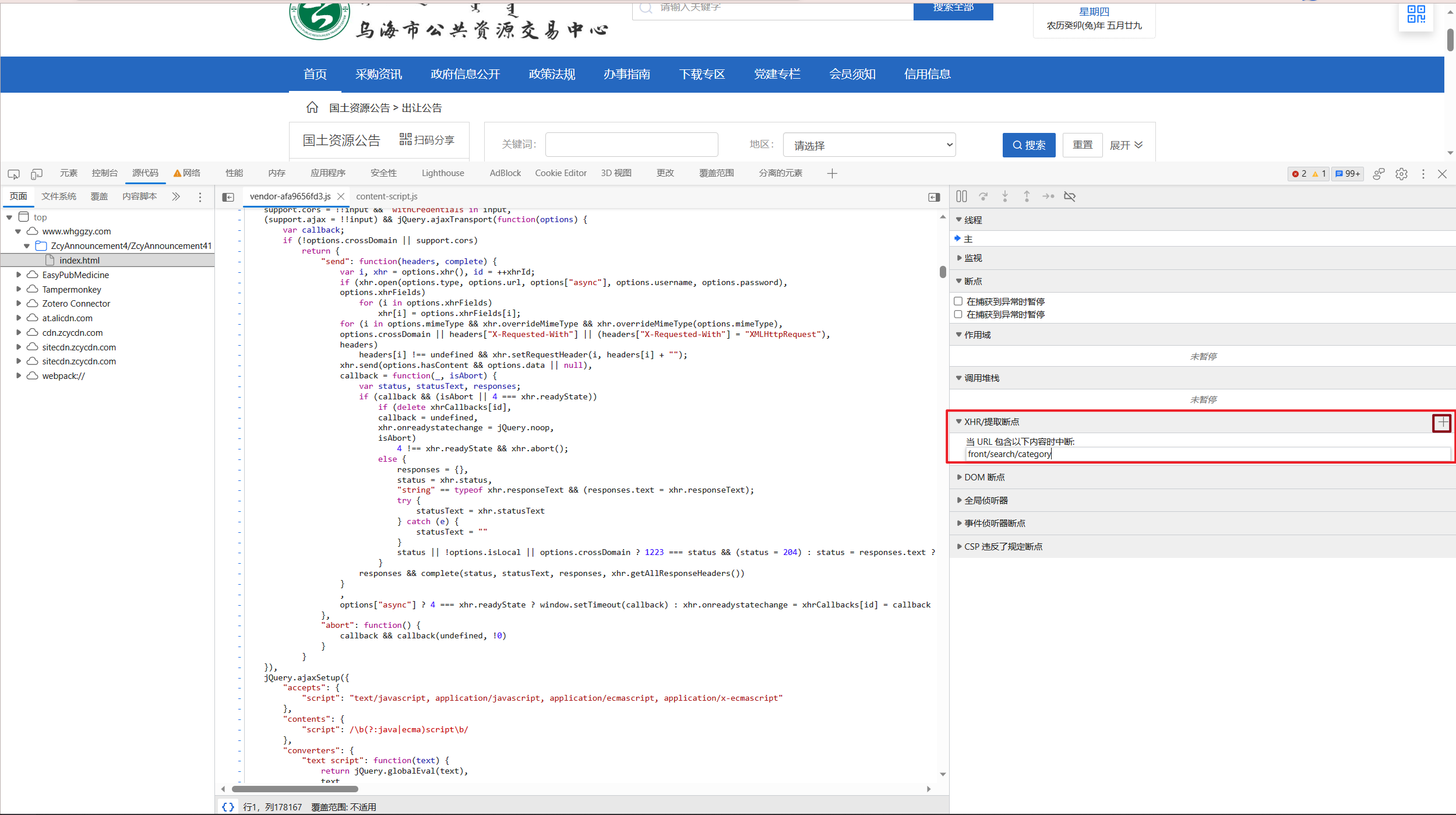
并没有我们想要的结果?点击侧边栏上策的横向箭头进入下一步。
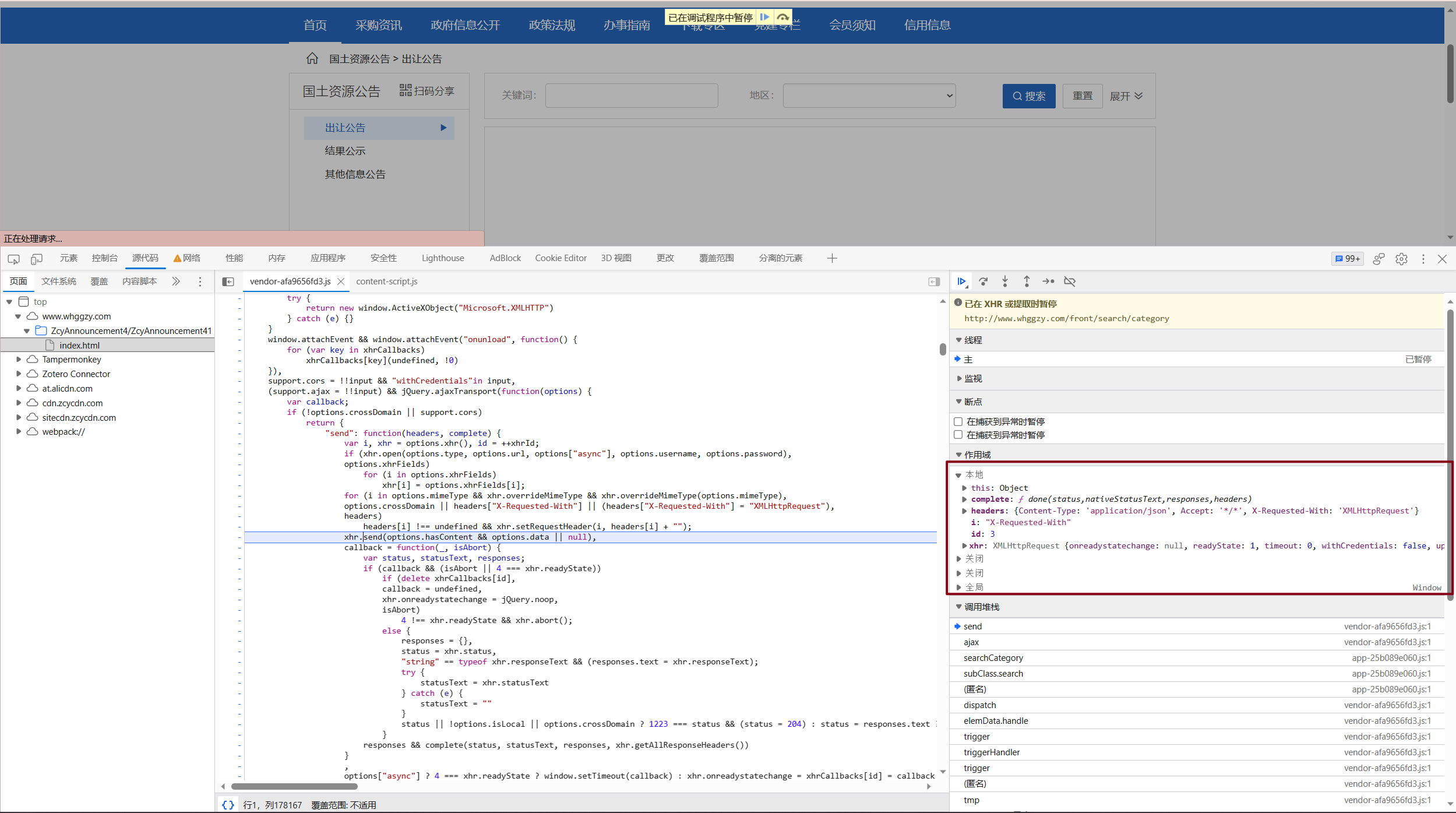
持续几次后我们会进入这一页面。
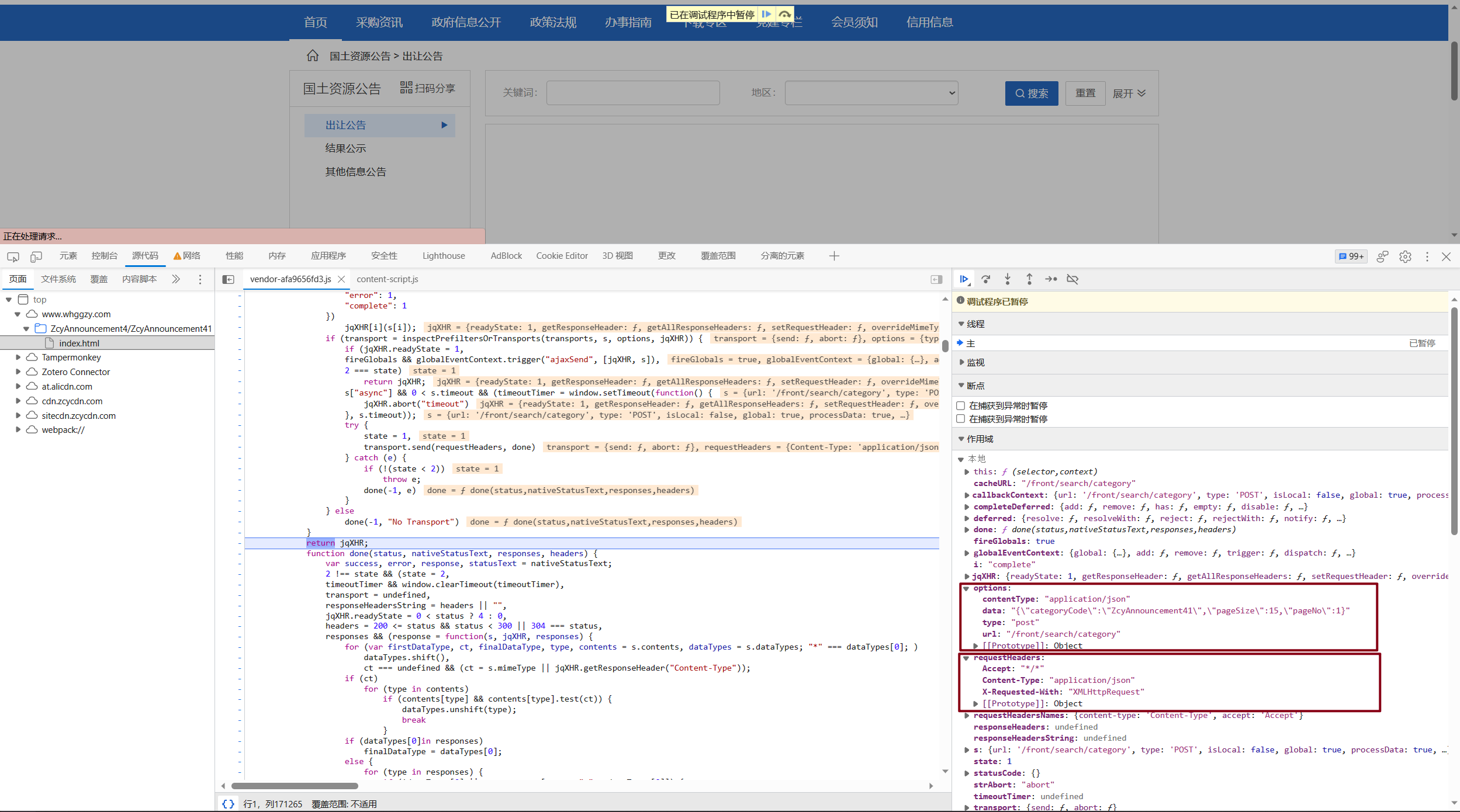
经过检查作用域中headers和options的参数,我们发现情况不对!
其一是RequestHeaders中校验了Accept,Content-Type,X-Requested-With三个标头,而我们并没有将其加入到我们的请求headers中。这种校验通常是由JavaScript来完成,而非直接传入服务端,否则在headers中加入病毒就可以直接威胁到服务器的安全。
其二是网站居然将data作为一个字符串传输!而在我们的视角中,浏览器会默认将这个字符串解析成json格式。了解了这点后,我们可以对request进行修改。
这实际上是浏览器防爬虫的一种手段,其他类似的方法还有将
get改post等。
1 | import requests |
好耶! 我们成功地获取了json文件(即类似python字典的这种格式)!
当然,通过response.text得到的是一个字符串,要想得到一个字典格式,我们需要使用response.json()或者是json.loads(response.text)的格式。
与json.loads相反的一个操作是json.dumps, 譬如我们前面想将data从字典形式变为字符串形式,就可用这一函数。1
2
3data = {"categoryCode": "ZcyAnnouncement41", "pageSize": 15, "pageNo": 1}
data = json.dumps(data)
#$ '{"categoryCode":"ZcyAnnouncement41","pageSize":15,"pageNo":1}'
